Open Theses
Important remark on this page
The following list is by no means exhaustive or complete. There is always some student work to be done in various research projects, and many of these projects are not listed here. For those, please have a look at the different members of the chair for more specific interests and contact them directly.
Abbreviations:
- PhD = PhD Dissertation
- BA = Bachelorarbeit, Bachelor's Thesis
- MA = Masterarbeit, Master's Thesis
- GR = Guided Research
- CSE = Computational Science and Engineering
Cloud Computing / Edge Computing / IoT / Distributed Systems
Background
With the rapid development of Cloud in the recent years, attempts have been made to bridge the widening gap between the escalating demands for complex simulations to be performed against tight deadlines and the constraints of a static HPC infrastructure by working on a Hybrid Infrastructure which consists of both the current HPC Clusters and the seemingly infinite resources of Cloud. Cloud is flexible and elastic and can be scaled as per requirements.
The BMW Group, which runs thousands of compute-intensive CAEx (Computer Aided Engineering) simulations every day needs to leverage the various offerings of Cloud along with optimal utilization of its current HPC Clusters to meet the dynamic market demands. As such, research is being carried out to schedule moldable CAE workflows in a Hybrid setup to find optimal solutions for different objectives against various constraints.
Goals
- The aim of this work is to develop and implement scheduling algorithms for CAE workflows on a Hybrid Cloud on an existing simulator using meta-heuristic approaches such as Ant Colony or Particle Swarm Optimization. These algorithms need to be compared against other baseline algorithms, some of which have already been implemented in the non-meta-heuristic space.
- The scheduling algorithms should be a based on multi-objective optimization methods and be able to handle multiple objectives against strict constraints.
- The effects of moldability of workflows with regards to the type and number of resource requirements and the extent of moldability of a workflow is to be studied and analyzed to find optimal solutions in the solution space.
- Various Cloud offerings should be studied, and the scheduling algorithms should take into account these different billing and infrastructure models while make decisions regarding resource provisioning and scheduling.
Requirements
- Experience or knowledge in Scheduling algorithms
- Experience or knowledge in the principles of Cloud Computing
- Knowledge or Interest in heuristic and meta-heuristic approaches
- Knowledge on algorithmic analysis
- Good knowledge of Python
We offer:
- Collaboration with BMW and its researchers
- Work with industry partners and giants of Cloud Computing such as AWS
- Solve tangible industry-specific problems
- Opportunity to publish a paper with your name on it
What we expect from you:
- Devotion and persistence (= full-time thesis)
- Critical thinking and initiativeness
- Attendance of feedback discussions on the progress of your thesis
The work is a collaboration between TUM and BMW
Apply now by submitting your CV and grade report to Srishti Dasgupta (srishti.dasgupta@bmw.de)
Background: Social good applications such as monitoring environments require several technologies, including federated learning. Implementing federated learning expects a robust balance between communication and computation costs involved in the hidden layers. It is always a challenge to diligently identify the optimal values for such learning architectures.
Keywords: Edge, Federated Learning, Optimization, Social Good,
Research Questions:
1. How to design a decentralized federated learning framework that applies to social good applications?
2. Which optimization parameters need to be considered for efficiently targeting the issue?
3. Are there any optimization algorithms that could deliver a tradeoff between the communication and computation parameters?
Goals: The major goals of the proposed research are given below:
1. To develop a framework that delivers a decentralized federated learning platform for social good applications.
2. To develop at least one optimization strategy that addresses the existing tradeoffs in hidden neural network layers.
3. To compare the efficiency of the algorithms with respect to the identified optimization parameters.
Expectations: The students are expected to have an interest to develop frameworks with more emphasis on federated learning; they have to committedly work and participate in the upcoming discussions/feedbacks (mostly online); they have to stick to the deadlines which will be specified in the meetings.
For more information, contact: Prof. Michael Gerndt (gerndt@tum.de) and Shajulin Benedict (shajulin@iiitkottayam.ac.in)
Background:
The Flux scheduler is a graph-based hierarchical scheduler for exascale systems that has been developed by the Lawrence Livermore Nation Laboratory to schedule HPC workloads with an efficient temporal management scheme across a range of HPC resources. Since it is graph-based, resource scheduling can be broken down to different levels. The flux scheduler has been extended to run on the Cloud as well and is flexible and elastic in its design.
Workflows represent a set of inter-dependent steps to achieve a particular goal. For example, a machine learning workflow is a series of steps for developing, training, validating and deploying machine learning models. In particular, a LLM(Large Language Model) workflow includes additional steps that define the complexities for training and deploying language models. These workflows are iterative in nature and each stage may inform changes in previous steps as the model’s limitations and new requirements emerge. Accordingly, the computational requirements vary and the hierarchical scheduler should adapt accordingly for each splitted data set by the resources (Cloud+HPC) growing and shrinking to reduce costs, deadlines and avail optimal resource utilization.
The work would be a part of the new field of Computer Science, namely Converged Computing, that aims to bridge the gap between Cloud technologies and the HPC world.
Goals:
- Extend the flux scheduler to allow for the growing and shrinking of Hybrid resources as per the demands of the individual jobs or tasks. The communication between these levels need to be extended as per the already established protocols of Flux.
- Implement an infrastructure that takes in an input of MLOps workflows and schedules these and the individual tasks according to the resource requirements in each iterative step by growing and shrinking according to the scheduler.
- Implement a Hybrid Infrastructure for the workflows to run on, thus taking advantage of the flexibility and elasticity of Cloud.
Requirements:
- Experience or knowledge or interest in Kubernetes and related cloud computing concepts.
- Preferred knowledge on MLOps workflows and other related topics
- Preferred experience on working with HPC systems and related libraries such as SLURM
- Knowledge on scheduling algorithms
- Basic knowledge of C++, Python, Linux Shell
- Basic Knowledge on TensorFlow or PyTorch
What we expect from you:
- Devotion and persistence(=full-time thesis)
- Critical thinking and ability to think out-of-the-box and take initiatives to explore ideas and use-cases
- Attendance of feedback discussions on the direction and progress of thesis
What we offer:
- Collaboration between a pioneering research center (Lawrence Livermore National Laboratory), a leader in the automobile industry (BMW) and the Technical University of Munich.
- Thesis in an area that is in the highest demand in the current industry; combining MLOps and infrastructure for MLOps, esp. in the Cloud.
- Supervision and collaboration from a multi-disciplinary team during the thesis.
- Opportunity to publish a paper with your name on it.
References:
1. flux-framework/flux-sched: Fluxion Graph-based Scheduler
2. Copy of HPC Knowledge Meeting: Converged Computing Flux Framework - Shared
The work is a collaboration between TUM, LLNL and BMW.
Apply now by submitting your CV and grade report to Srishti Dasgupta(srishti.dasgupta@bmw.de/srishti.dasgupta@tum.de)
Modeling and Analysis of HPC Systems/Applications
Background & Context
Most of the energy efficiency projects in heterogeneous High Performance Computing (HPC) focus on run-time informed, post-mortem optimizations. While this approach is effective, it requires at least one execution on an application to collect the required input for the optimisations and another run to actually benefit from an optimised execution of an application.
Within the broader context of this project, we focus on a static, compile-time informed, pre-executional optimisations. We aim to implement a compiler pass that is able to optimise for energy rather than for performance during the compilation process. This project aims to extend our "EPI Pen" project - a tool that is designed to measure, analyse, visualise, and optimise the energy consumption of a heterogeneous HPC system in a vendor agnostic way.
With this approach, we are able to optimise the energy consumption of an application without needing developers to change their codes or system administrators to change the settings of their HPC systems.
Goals & Expected Outcomes
This project consists of various sub-projects which may be addressed in individual thesis/ projects.
Extension of Calibration/ Measurement Benchmarks
"EPI Pen" currently uses a set of naively collected, unoptimised microbenchmarks to collect energy information of a compute node. This sub project focuses on revisiting the set of microbenchmarks of the calibrations phase and to replace/ extend/ modify these calibration benchmarks to reach the following goals:
- Stress all aspects of a GPU (compute/ data movement)
- Reduce the time-to-calibrate
- Extend for other architectures (newer AMD and NVIDIA GPUs currently in focus)
- Extend for other accelerators, e.g., FPGAs
Mapping of Energy Measurements from Hardware Counters to LLVM IR / Source Code
"EPI Pen" currently focuses on run-time measurements based on hardware counters measured on real silicon. For reaching the goal of a compile-time analysis framework, the measurements performed on real hardware counters have to be mapped to their respective representations in LLVM IR/ source code. The following, naive approach outlines one possible way to achieve that goal:
- Define nano benchmarks: For each operation, define a nano benchmark that only performs this specific operation
- Measure hardware counters for nano benchmarks: For each nano benchmark, check which hardware counters are stressed
- Measure the consumed energy for each nano benchmarks: Extrapolate for each nano benchmark the consumed energy
- Create mapping between measured energy and LLVM IR/ source code: Map the measurement results to their higher-level representations
- Analysis & discussion of the findings; verification on more complex (micro-)benchmarks
Implementation of Visualisation Framework
"EPI Pen" currently relies on manual inspection and visualisation of the research scientist.
This part of the project aims to close that gap by implementing a visualisation framework that is capable of dealing with different kinds of abstraction layers (hardware counter, intermediate representation, source code) and aggregation types (per node, per architecture, per instruction, ...).
The input for this visualisation are the outputs of the abovementioned sub-projects. As the main focus of this sub-project is analysis and visualisation, we recommend the usage of Python and/ or other data exploration friendly programming languages.
Prerequisites
- Experience in low level programming languages (assembly, C/++)
- Interest and/ or experience in compiler technologies, especially with the LLVM compiler suite
Contact
The topics mentioned above are only an extract of the actually available topics regarding "EPI Pen".
Feel free to contact karlo.kraljic@tum.de and get a broader insight into the currently available topics.
Background & Context
Most of the energy efficiency projects in heterogeneous High Performance Computing (HPC) focus on run-time informed, post-mortem optimizations. While this approach is effective, it requires at least one execution on an application to collect the required input for the optimisations and another run to actually benefit from an optimised execution of an application.
Within the broader context of this project, we focus on a static, compile-time informed, pre-executional optimisations. We aim to implement a compiler pass that is able to optimise for energy rather than for performance during the compilation process. This project aims to define a set of exchangeable functions and what costs are related to their exchange, either with regards to energy of computational precision.
With this approach, we are able to optimise the energy consumption of an application without needing developers to change their codes or system administrators to change the settings of their HPC systems.
Goals & Expected Outcomes
This work provides the skeleton for replacing less energy-efficient with more energy-efficient functions and discusses the computational precision losses (and hence, implicitly, suitable use cases) associated to this kind of optimisation.
The first goal of this work is to analyse all (or a meaningful subset of) instructions and define so called "equivalence" classes, i.e., sets of operations that perform semantically similar operations such as adding or multiplying or moving data.
The second goal is to define "transition" function to replace one function within a equivalence class by another, e.g., one transition function my transit the fused multiply-add into a set of load/ multiply/ add/ store operations without loosing precision. Other transition functions may be less trivial, i.e., replacing a sine function with Taylors approximation.
The third goal is to evaluate these "transition" functions in terms of computational precision and energetic efficiency.
Prerequisites
- Experience in low level programming languages (assembly, C/++)
- Interest and/ or experience in compiler technologies, especially with the LLVM compiler suite
Contact
Karlo Kraljic (karlo.kraljic@tum.de)
Background and Motivation:
The ever increasing power consumption of supercomputers has been one of the major concerns in the HPC community since mid2000s. Therefore, there have been a variety of studies to measure and manage the power consumption of HPC systems from diverse perspectives since then. However to the best of our knowledge, analysis of power consumption on the level of library function call granularity hasn’t been investigated. This approach enables a different perspective into library’s and application’s power consumption and carbon emissions. As modern HPC applications use libraries heavily from communication, computation and memory operations, it is interesting to inspect power consumptions of the different function calls from these library functions as much as the whole application itself. By these measurements the characteristics of individual functions in the libraries on different architectures can be analysed and optimized.
Function interception is a common method used to place introspection points for instrumentation of applications. This method particularly useful when update in the source code is not desired or feasible to mark instrumentation points in the source code. There are two techniques that are commonly used for application interception at function call level. One is by utilizing function wrappers and dynamic linking the other is binary instrumentation to update the application binary. Both approaches have their strengths however for this project we will focus on function wrappers and dynamic linking approach.Wrapper generation paper: https://link.springer.com/chapter/10.1007/978-3-031-69577-3_8
Lastly the roofline model has been a standard way to understand rough characteristics of the architecture capabilities as well as the application performance in relation to the architecture capabilities. There are multiple different derivations of the model that enable slightly different or more detail into the architecture’s capabilities. For example, the cache aware roofline model is an extension of the standard roofline model that considers the effects of the memory hierarchy in the system on to the roofline model, hence presents a more realistic model. Similarly the roofline model of energy considers similar principles as the standard roofline model but it takes energy as performance metric of interest instead of traditional time metric. Hence, the flops per second is replaced by flops per joule and the operational intensity(flops per bytes transferred ). This model represents an upper bound for achievable energy efficiency of the system. Using these two roofline models it is possible to compare the time vs power efficiency of the library functions on each architecture.https://ieeexplore.ieee.org/document/6506838 and https://ieeexplore.ieee.org/document/6569852
Research question:
Can we optimize application’s power consumption and carbon emission on different CPU architectures by profiling the power consumption of individual library function calls ?
Can we make suggestions to the user for different stages of the application to optimize power consumption via techniques like down clocking ?
Goal:
Suggesting users certain libraries or library implementations over others depending on their power consumption characteristics when used with different applications on different architectures.
Suggesting users techniques to optimize their power consumption depending on the application phases or library calls made by the application.
Requirements:
1. Measurements must be at every library call function granularity.
2. Measurements must be statistically significant.
3. Measurements must include power consumption and carbon emission and other possibly related PAPI measurements to be able to relate power consumption to function characteristics
(FLOPS for computation function, Network utilisation for communication library functions )
4. The measurements should be interpreted to make suggestions to the user about how to optimize the applications power consumption on specific architectures.
Method:
- The instrumentation points are at every library function call. For intercepting the library function calls we use a wrapIt wrapper generator to generate the interface for tool changing and tool generation.
- Implement measurement code for carbon emission and power consumption of each function call.
- Take measurements by WrapIt interface and plot histogram and timeline of power consumption of each library function. Characterise the power relation of the application and the libraries.
- Compare the measurements to the power roofline and
Evaluation method:
- Extracting Power Measurements:
We collect data at every library function call by using the WrapIt tools. These measurements will be at function call granularity and will report the power consumption and carbon emission of the entire runtime of the functions at each call. By analysing the measurements we can characterize the power consumption and carbon emission of library functions on different CPUs. These measurements are used to identify the energy and carbon bottleneck functions.
- Function-granular energy and carbon analysis using an energy version of the roofline model:
Identifying the energy and carbon sweet spots, and suggesting users how the code should be optimized.
- Relational analysis between Cache aware roofline model and Roofline model of Energy:
Identifying the relationship between cache aware roofline model and Roofline model of Energy on function granularity.
- Extending the energy roofline in order to take some additional aspects into account, such as cache hits/misses and clock frequency.
Evaluation/Verification and Contribution Outline:
Metrics to measure:
- Rapl power counters
Other Possible metrics to measure to relate with power consumption:
By PAPI Counters:
- Memory Bandwidth
- Flop rate
- Memory Utilization
Probable Libraries to Introspect :
- Hypre: Linear Solver library. Potentially meaningful for flop rate, memory bandwidth, cache miss and power consumption measurements.
- Umpire: Portability layer for memory management (malloc,free etc.). Used by hypre
Probable applications:
- AMG (uses MPI,hypre and Umpire)
- Gene (real life code in Fortran has Communication, memory and computation libraries)
See also:
Power/performance modeling: https://link.springer.com/content/pdf/10.1007/978-3-030-50743-5_18.pdf
Power/performance modeling2: https://dl.acm.org/doi/pdf/10.1145/3547276.3548630
Software carbon emission estimation: https://dl.acm.org/doi/pdf/10.1145/3631295.3631396
Carbon estimation tool (WattTime): https://docs.watttime.org/
The Cerebras CS-2 wafer-scale engine (https://www.cerebras.ai) is a novel HPC system at LRZ that integrates 850.000 cores and 40GB of memory on the worlds largest chip for processing AI workloads. This system is installed and operated at LRZ.
This thesis will systematically benchmark and analyze the energy consumption of representative ML workloads (e.g., BERT pre-training, GPT-2 fine-tuning, ViTs) and HPC kernels (e.g., 2D/3D stencils, dense matrix multiplies, mini-DFT) on the Cerebras CS-2 wafer-scale engine, using on-chip telemetry and external meters to gather fine-grained metrics—total joules, energy per iteration/epoch/inference, and energy per FLOP—across varied batch sizes and problem scales; it will uncover how compute density, memory access patterns, and communication intensity shape power draw over time, pinpoint energy bottlenecks in phases like initialization or convergence, and propose software- and hardware-level optimizations.
Contact:
Jophin John at LRZ (Jophin.John@lrz.de)
Co-supervized: Prof. Michael Gerndt
This work will be largely run and evaluated on the HPC systems of LRZ, and will also be co-advised by LRZ colleagues.
Background:
CAPS TUM has previously developed a framework for automatic running of various benchmarks, which enables fine-grained level of detail with respect to the configuration of the benchmark and the resources it runs on. There are multiple popular benchmarks included, stressing different aspects of the system, such as memory, cache or compute. More benchmarks can easily be added. As a second step, this framework automatically processes the raw data from the runs to provide basic statistical analysis. Finally, the data is either visualized or it is loaded by the sys-sage library(paper) for further use, such as for scheduling and mapping processes/tasks on resources (nodes, sockets, cores,..). The main focus of the framework is to seamlessly collect performance data and to evaluate performance variations on CPUs in (large-scale production) HPC systems.
Parallel to this, LRZ has developed AutoBench, which is a platform for automated and reproducible benchmarking in HPC Testbeds. It is capable of setting and controlling different SW and HW knobs, having more control over the exact configuration of the test system. It enables benchmarking the tested system with different configurations, so that the effect of these configurations can also be analyzed.
Task:
The first part of this thesis lies in integrating these two approaches, so that we can benefit from the fine granularity and performance variations focus of the CAPS tool as well as from the control over the system configuration on from the LRZ side.
Once the integration is in place, there are multiple analyses and experiments to have a look at. Due to time constraints, we will likely restrict the work to one or two of the following:
- Exploring variability in different configurations: can we see some differences in the performance variability of the benchmarks when we run them on differently configured nodes? (do all benchmarks behave the same variability differences or are there differences?)
- Finding optimal configurations for different workloads: do all benchmarks show higher/lower variability with certain config? is some configuration better for some benchmark and another config for another benchmark? For instance, can we find (different) optimal configurations for compute- vs memory-heavy benchmarks/jobs?
- Exploring differences in variability on different configurations and different nodes: Comparing always nodes with identical configuration, are some nodes always performing worse than others regardless of the configuration? Are there some configurations that amplify/reduce the differences in the perf. variability?
Contact:
In case of interest, please contact Stepan Vanecek (stepan.vanecek at tum.de) of the Chair for Computer Architecture and Parallel Systems (Prof. Schulz) and/or Amir Raoofy (Amir.Raoofy at lrz.de) from LRZ and attach your CV & transcript of records.
Published on 06.03.2025
Background:
HPC systems are becoming increasingly heterogeneous as a consequence of the end of Dennard scaling, slowing down of Moore's law, and various emerging applications including LLMs, HPDAs, and others. At the same time, HPC systems consume a tremendous amount of power (can be over 20MW), which requires sophisticated power management schemes at different levels from a node component to the entire system. Driven by those trends, we are studing on sophisticated resource and power management techniques specifically tailored for modern HPC systems, as a part of Regale project (https://regale-project.eu/).
Research Summary:
In this work, we will focus on co-scheduling (co-locating multiple jobs on a node to minimize the resource wastes) and/or power management on HPC systems, with a particular focus on heterogeneous computing systems, consisting of multiple different processors (CPU, GPU, etc.) or memory technologies (DRAM, NVRAM, etc.). Recent hardware components generally support a variety of resource partitioning and power control features, such as cache/bandwidth partitioning, compute resource partitioning, clock scaling, power/temperature capping, and others, controllable via previlaged software. You will first pick up some of them and investigate their impact on HPC applications in performance, power, energy, etc. You will then build an analytical or emperical model to predict the impact and develop a control scheme to optimize the knob setups using your model. You will use hardware available in CAPS Cloud (https://www.ce.cit.tum.de/caps/hw/caps-cloud/) or LRZ Beast machines (https://www.lrz.de/presse/ereignisse/2020-11-06_BEAST/) to conduct your study.
Requirements:
- Basic knowledge/skills on computer architecture, high performance computing, and statistics
- Basic knowledge/skills on surrounding areas would also help (e.g., machine learning, control theory, etc.).
- In genreral, we would be very happy with guiding anyone self-motivated, capable of critical thinking, and curious about computer science.
- We don't want you to be too passive – you are supposed to think/try yourself to some extend, instead of fully following our instructions step by step.
- If your main goal is passing with any grade (e.g., 2.3), we'd suggest you look into a different topic.
See also our former studies:
- Urvij Saroliya, Eishi Arima, Dai Liu, Martin Schulz "Hierarchical Resource Partitioning on Modern GPUs: A Reinforcement Learning Approach" In Proceedings of IEEE International Conference on Cluster Computing (CLUSTER), pp.185-196, Nov. (2023)
- Issa Saba, Eishi Arima, Dai Liu, Martin Schulz "Orchestrated Co-Scheduling, Resource Partitioning, and Power Capping on CPU-GPU Heterogeneous Systems via Machine Learning" In Proceedings of 35th International Conference on Architecture of Computing Systems (ARCS), pp.51-67, Sep. (2022)
- Eishi Arima, Minjoon Kang, Issa Saba, Josef Weidendorfer, Carsten Trinitis, Martin Schulz "Optimizing Hardware Resource Partitioning and Job Allocations on Modern GPUs under Power Caps" In Proceedings of International Conference on Parallel Processing Workshops, no. 9, pp.1-10, Aug. (2022)
- Eishi Arima, Toshihiro Hanawa, Carsten Trinitis, Martin Schulz "Footprint-Aware Power Capping for Hybrid Memory Based Systems" In Proceedings of the 35th International Conference on High Performance Computing, ISC High Performance (ISC), pp.347--369, Jun. (2020)
Contact:
Dr. Eishi Arima, eishi.arima@tum.de, https://www.ce.cit.tum.de/caps/mitarbeiter/eishi-arima/
Prof. Dr. Martin Schulz
Memory Management and Optimizations on Heterogeneous HPC Architectures
Background:
Compute Express Link (CXL) is an emerging interconnect technology designed for efficient data exchange between processors and memory devices. In particular, CXL.mem, built on top of PCI Express, enables memory expansion and low-latency access to external memory resources.
Recent CXL Type-3 memory devices (CXL 3.1 and later) allow memory buffers to be shared across multiple compute nodes. This capability introduces a new paradigm for data exchange that may significantly reduce the overhead associated with traditional communication mechanisms.
Communication-heavy operations are a common performance bottleneck in distributed systems. One prominent example is data redistribution during dynamic resource reconfiguration at runtime, where data must be migrated between nodes as the allocation of computational resources changes. Reducing the cost of such redistribution could greatly improve the practicality and performance of dynamic resource management in distributed applications.
Thesis Goal:
The goal of this thesis is to quantify the performance potential of CXL Type-3 memory devices for dynamic data redistribution, and to compare this approach with conventional MPI + DRAM–based communication mechanisms.
Tasks:
- Extend an existing data redistribution library to support 2D and 3D array redistribution.
- Develop a parameterizable workload operating on 1D, 2D, and 3D computational domains.
- [If time permits] Develop data redistribution for an AI workload
- Implement and trace the execution of a baseline MPI + DRAM-based redistribution workflow.
- Use the collected traces as input to a CXL.mem-based performance model.
- Compare the performance characteristics of CXL-based memory sharing with the traditional MPI + DRAM communication approach.
Expected Outcomes:
- A performance comparison of CXL.mem-based and MPI-based data redistribution
- Insights into when CXL memory sharing can outperform traditional communication
- Recommendations for dynamic resource management systems using CXL
Required Background:
- Experience with parallel programming
- Proficiency in C programming
Contact:
In case of interest, please contact Stepan Vanecek (stepan.vanecek@tum.de) or Dominik Huber (domi.huber@tum.de) at the Chair for Computer Architecture and Parallel Systems (Prof. Schulz) and attach your CV & transcript of records.
Background:
Mitos, originally developed at CAPS TUM, is an application performance monitoring tool that collects detailed PMU data on real hardware. We adapted it for performance modeling, focusing on MPI communication overheads using the Hockney model. Currently, it supports send-recv (point-to-point) MPI operations, but lacks coverage for collectives (e.g., Allgather). The modeling effort targets comparing classical MPI with MPI-over-CXL for each MPI call in user code, leveraging CXL’s message-free cross-node shared memory to assess potential benefits.
This thesis extends Mitos to include collectives and develops a CXL model, drawing on "MPI Allgather Utilizing CXL Shared Memory Pool in Multi-Node Computing Systems" (IEEE BigData 2024, https://ieeexplore.ieee.org/document/10825804), which proposes a CXL-based Allgather method with shared memory emulation (e.g., QEMU).
Task:
The goal is to enhance Mitos for modeling MPI-over-CXL performance, focusing on:
- Adjusting MPI overhead: Replace Hockney with a LogP* variant (e.g., gap and overhead terms) for both point-to-point and collectives. Use tools such as NetGauge to measure parameters on real clusters, and integrate this tool in the workflow/toolchain.
- Developing a CXL model: Implement a CXL simulation/emulation layer based on the referenced paper, modeling shared memory pools for all MPI calls (send-recv and collectives) to compare classical MPI vs. MPI-over-CXL performance per call. Validate via benchmarks on multi-node setups.
This supports detailed analysis of CXL’s impact on MPI communication, aiding workload optimization. Enhance Mitos’ output for modeling integration. Master students should include scalability analysis; Bachelor students focus on core implementation and validation.
Contact:
In case of interest, please contact Stepan Vanecek (stepan.vanecek@tum.de) at the Chair for Computer Architecture and Parallel Systems (Prof. Schulz) and attach your CV & transcript of records.
Published on 27.9.2025
Background:
MT4G (https://github.com/caps-tum/mt4g) is an open-source, vendor-agnostic tool for auto-discovery of NVIDIA and AMD GPU compute and memory topologies. It combines APIs with over 50 microbenchmarks and statistical methods (e.g., Kolmogorov-Smirnov test) to detect attributes like cache sizes, latencies, and bandwidths. Demonstrated on 10 GPUs, it integrates into workflows such as GPU performance modeling, GPUscout bottleneck analysis, and dynamic resource partitioning.
Currently, MT4G focuses on memory subsystems. This thesis aims to extend it to compute capabilities, identifying key aspects like instruction throughput, thread scheduling efficiency, register pressure, and SIMD efficiency—beyond your suggested directions.
Task:
The goal is to design and implement compute-focused microbenchmarks in MT4G, ensuring portability via HIP.
Regarding your directions:
- Benchmark datatype performance (e.g., FLOPS for FP64, FP32, INT64, INT32) using compute-intensive kernels; fair comparison via normalization by cores, clock rates, and warp/wavefront sizes.
- Benchmark engines like NVIDIA Tensor Cores and AMD Matrix Cores via standardized (e.g., GEMM) or specialized operations; investigate on fairness by separate vendor reports, acknowledging non-equivalent features and limiting to comparable GPUs.
Contact:
In case of interest, please contact Stepan Vanecek (stepan.vanecek@tum.de) at the Chair for Computer Architecture and Parallel Systems (Prof. Schulz) and attach your CV & transcript of records.
Published on 25.9.2025
Various MPI-Related Topics
Please Note: MPI is a high performance programming model and communication library designed for HPC applications. It is designed and standardised by the members of the MPI-Forum, which includes various research, academic and industrial institutions. The current chair of the MPI-Forum is Prof. Dr. Martin Schulz. The following topics are all available as Master's Thesis and Guided Research. They will be advised and supervised by Prof. Dr. Martin Schulz himself, with help of researches from the chair. If you are very familiar with MPI and parallel programming, please don't hesitate to drop a mail to Prof. Dr. Martin Schulz. These topics are mostly related to current research and active discussions in the MPI-Forum, which are subject of standardisation in the next years. Your contribution achieved in these topics may make you become contributor to the MPI-Standard, and your implementation may become a part of the code base of OpenMPI. Many of these topics require a collaboration with other MPI-Research bodies, such as the Lawrence Livermore National Laboratories and Innovative Computing Laboratory. Some of these topics may require you to attend MPI-Forum Meetings which is at late afternoon (due to time synchronisation worldwide). Generally, these advanced topics may require more effort to understand and may be more time consuming - but they are more prestigious, too.
LAIK is a new programming abstraction developed at LRR-TUM
- Decouple data decompositionand computation, while hiding communication
- Applications work on index spaces
- Mapping of index spaces to nodes can be adaptive at runtime
- Goal: dynamic process management and fault tolerance
- Current status: works on standard MPI, but no dynamic support
Task 1: Port LAIK to Elastic MPI
- New model developed locally that allows process additions and removal
- Should be very straightforward
Task 2: Port LAIK to ULFM
- Proposed MPI FT Standard for “shrinking” recovery, prototype available
- Requires refactoring of code and evaluation of ULFM
Task 3: Compare performance with direct implementations of same models on MLEM
- Medical image reconstruction code
- Requires porting MLEM to both Elastic MPI and ULFM
Task 4: Comprehensive Evaluation
ULFM (User-Level Fault Mitigation) is the current proposal for MPI Fault Tolerance
- Failures make communicators unusable
- Once detected, communicators an be “shrunk”
- Detection is active and synchronous by capturing error codes
- Shrinking is collective, typically after a global agreement
- Problem: can lead to deadlocks
Alternative idea
- Make shrinking lazy and with that non-collective
- New, smaller communicators are created on the fly
Tasks:
- Formalize non-collective shrinking idea
- Propose API modifications to ULFM
- Implement prototype in Open MPI
- Evaluate performance
- Create proposal that can be discussed in the MPI forum
ULFM works on the classic MPI assumptions
- Complete communicator must be working
- No holes in the rank space are allowed
- Collectives always work on all processes
Alternative: break these assumptions
- A failure creates communicator with a hole
- Point to point operations work as usual
- Collectives work (after acknowledgement) on reduced process set
Tasks:
- Formalize“hole-y” shrinking
- Proposenew API
- Implement prototype in Open MPI
- Evaluate performance
- Create proposal that can be discussed in the MPI Forum
With MPI 3.1, MPI added a second tools interface: MPI_T
- Access to internal variables
- Query, read, write
- Performance and configuration information
- Missing: event information using callbacks
- New proposal in the MPI Forum (driven by RWTH Aachen)
- Add event support to MPI_T
- Proposal is rather complete
Tasks:
- Implement prototype in either Open MPI or MVAPICH
- Identify a series of events that are of interest
- Message queuing, memory allocation, transient faults, …
- Implement events for these through MPI_T
- Develop tool using MPI_T to write events into a common trace format
- Performance evaluation
Possible collaboration with RWTH Aachen
PMIxis a proposed resource management layer for runtimes (for Exascale)
- Enables MPI runtime to communicate with resource managers
- Come out of previous PMI efforts as well as the Open MPI community
- Under active development / prototype available on Open MPI
Tasks:
- Implement PMIx on top of MPICH or MVAPICH
- Integrate PMIx into SLURM
- Evaluate implementation and compare to Open MPI implementation
- Assess and possible extend interfaces for tools
- Query process sets
MPI was originally intended as runtime support not as end user API
- Several other programming models use it that way
- However, often not first choice due to performance reasons
- Especially task/actor based models require more asynchrony
Question: can more asynchronmodels be added to MPI
- Example: active messages
Tasks:
- Understand communication modes in an asynchronmodel
- Charm++: actor based (UIUC)•Legion: task based (Stanford, LANL)
- Propose extensions to MPI that capture this model better
- Implement prototype in Open MPI or MVAPICH
- Evaluation and Documentation
Possible collaboration with LLNL and/or BSC
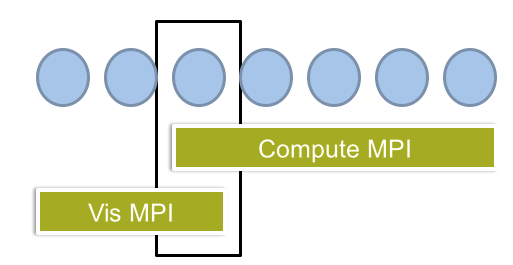
MPI can and should be used for more than Compute
- Could be runtime system for any communication
- Example: traffic to visualization / desktops
Problem:
- Different network requirements and layers
- May require different MPI implementations
- Common protocol is unlikely to be accepted
Idea: can we use a bridge node with two MPIs linked to it
- User should see only two communicators, but same API
Tasks:
- Implement this concept coupling two MPIs
- Open MPI on compute cluster and TCP MPICH to desktop
- Demonstrate using on-line visualization streaming to front-end
- Document and provide evaluation
- Warning: likely requires good understanding of linkers and loaders
Field-Programmable Gate Arrays
Field Programmable Gate Arrays (FPGAs) are considered to be the next generation of accelerators. Their advantages reach from improved energy efficiency for machine learning to faster routing decisions in network controllers. If you are interested in one of it, please send your CV and transcript of records to the specified Email address.
Our chair offers various topics available in this area:
- Quantum Computing: Your tasks will be to explore architectures that harness the power of traditional computer architecture to control quantum operations and flows. Now we focus on superconducting qubits & neutral atoms control. (xiaorang.guo@tum.de)
- Deep Learning: We explore various ways to optimize and deploy Deep Learning architectures on FPGA. Your tasks would be to explore the customizability of automated pipeline toolchains or optimize existing Deep Learning architectures for efficient porting and inference. (cedric.leonard@tum.de)
- Open-Source EDA tools: Explore different open-source EDA tools, you can find more infomation on my webpage (dirk.stober@tum.de)
- HLS and Memory: I offer different topics related to High Level Synthesis (HLS) and memory on FPGAs, you can find more infomation on my webpage (dirk.stober@tum.de)
- Direct network operations: Here, FPGAs are wired closer to the networking hardware itself, hence allows to overcome the network stack which a regular CPU-style communication would be exposed to. Your task would be to investigate FPGAs which can interact with the network closer than CPU-based approaches. ( martin.schreiber@tum.de )
- Linear algebra: Your task would be to explore strategies to accelerate existing linear algebra routines on FPGA systems by taking into account applications requirements. ( martin.schreiber@tum.de )
- Varying accuracy of computations: The granularity of current floating-point computations is 16, 32, or 64 bit. Your work would be on tailoring the accuracy of computations towards what's really required. ( martin.schreiber@tum.de )
- ODE solver: You would work on an automatic toolchain for solving ODEs originating from computational biology. ( martin.schreiber@tum.de )
Goal
Explore and model the performance of AMD Deep learning Processing Unit (DPU) under certain settings and model configurations.
Requirements
- Basic knowledge of Deep Learning concepts (Pytorch)
- Experienced with Linux and shell utilities
Optional/Helpful
- Familiar with embedded systems and FPGA programming
Description
The growing number of satellites in the New space era calls for an ever-increasing need of automation and decision-making onboard. Machine Learning methods, particularly Deep Learning (DL), have long proved to be state of the art in many Earth Observation applications. However, deploying such computationally intensive method onboard is non-trivial, especially considering the space environment constraints, such as power limitation or radiation. FPGA-based devices constitute a good solution, combining radiation-tolerant designs and reprogrammability for optimal usage of the available hardware resources. Modern automatic implementation toolchains mitigate the design complexity inherent to FPGAs by providing abstract deployment workflows. In particular, AMD Vitis AI [1] leverages a Deep learning Processing Unit (DPU) to accelerate DL models, such as CNNs.
The objective of this thesis is to explore the performance modelling of the Vitis AI DPU for Remote Sensing use cases. Two specific Machine Learning tasks will be explored: Landcover classification and learned data compression, both using the EuroSAT dataset [2]. The thesis focuses on providing a comprehensive performance analysis of AMD's DPU in terms of several relevant metrics, such as task performance (e.g., accuracy or compression rate), memory bandwidth, throughput, latency, and if possible power consumption. The deployment and measurements will be done on a Zynq UltraScale+ (MPSoC ZCU102 Evaluation Kit).
Contacts
In case of interest, please contact Cédric Léonard (cedric.leonard(at)dlr.de) and Dirk Stober (dirk.stober(at)tum.de).
References
[1] AMD. (2019). Vitis AI Overview v3.5 User Guide. Vitis AI User Guide (UG1414).
[2] Helber, P., Bischke, B., Dengel, A., & Borth, D. (2017, August 31). EuroSAT: A Novel Dataset and Deep Learning Benchmark for Land Use and Land Cover Classification. arXiv.
Further reading
[3] Léonard, C., Stober, D., & Schulz, M. (2025). FPGA-Enabled Machine Learning Applications in Earth Observation: A Systematic Review. arXiv.
[4] Gomes, C., Wittmann, I., Robert, D., Jakubik, J., Reichelt, T., Martone, M., Maurogiovanni, S., Vinge, R., Hurst, J., Scheurer, E., Sedona, R., Brunschwiler, T., Kesselheim, S., Batic, M., Stier, P., Wegner, J. D., Cavallaro, G., Pebesma, E., Marszalek, M., … Albrecht, C. M. (2025). Lossy Neural Compression for Geospatial Analytics: A Review. arXiv.
Quantum Computing
Background
Quantum computing faces a critical challenge: the high error rates of qubits. Quantum error correction (QEC) codes (e.g., surface codes) protect quantum information through redundancy and real-time error mitigation. However, practical implementations require efficient hardware platforms. FPGAs, with their parallel processing capabilities and low latency, are ideal for prototyping QEC schemes. This project aims to implement a QEC code (e.g., surface code) on an FPGA and explore its potential for real-time error correction.
Task
1. Study the principles of QEC codes; investigate decoding algorithms for QEC (e.g., minimum-weight perfect matching (MWPM), QULATIS…)
2. Hardware Implementation:
- Design and implement the decoder on an FPGA.
- Optimize resource utilization (logic units, memory) and latency, leveraging FPGA parallelism.
3. Performance Evaluation:
- Analyze error correction success rates, latency, and resource efficiency via simulations and hardware testing.
- Compare the impact of code distances on the correction performance.
Requirement
Experience in programming with VHDL/Verilog. Understand basic quantum theory.
Contact:
In case of interest or any questions, please contact Xiaorang Guo (xiaorang.guo@tum.de) at the Chair for Computer Architecture and Parallel Systems (Prof. Schulz) and attach your CV & transcript of records.
Background: Neutral atom (NA) detection plays a crucial role in NA quantum computer in terms of state preparation and readout. Traditional detection methods often rely on computationally intensive image processing techniques that can be inefficient for real-time applications. Implementing an ML-based detection algorithm on FPGA provides a hardware-accelerated solution with low latency, high throughput, and energy efficiency, making it suitable for large-scale atom array experiments.
Tasks
1. Evaluate various ML models (e.g., CNNs, Mamba models) and train them on labeled atom datasets.
2. Hardware Implementation:
- Optimize the trained model for FPGA deployment, eg, with tiling or tensor core-based architectures
- Aim to balence the resource utilization (logic units, memory) and latency, leveraging FPGA parallelism.
3. Performance Evaluation:
- Compare accuracy, inference latency with C++/python based methods
Required Skills & Resources:
- Have backgrounds in ML
- Experience with FPGA programming (e.g., VHDL, Verilog, or HLS)
- Familiarity with PYNQ, Xilinx tools, or equivalent platforms
Contact: Xiaorang Guo(xiaorang.guo@tum.de), Jonas Winklmann (jonas.winklmann@tum.de), Prof. Martin Schulz
Various Thesis Topics in Collaboration with Leibniz Supercomputing Centre
We have a variety of open topics. Get in contact with Amir Raoofy
The AI landscape has been transformed by foundation models that can be adapted for diverse tasks. Evidence increasingly shows a clear relationship between model scale and capability, systems with hundreds of billions of parameters consistently achieve superior results compared to their more compact alternatives. However, this scalability advantage introduces substantial practical barriers. The computational demands of training such massive neural networks require sophisticated infrastructure and careful resource management, making efficient training strategies essential for advancing the field.
In this thesis you will develop and apply roofline models for transformer-based LLMs under multinode training. You measure compute throughput and memory-bandwidth utilization on Intel PVC GPUs and analyze kernel-level performance (attention, MLP, embedding, normalization). Finally, you evaluate communication overheads (all-reduce, tensor/pipe parallelism) and their impact on scaling and identify underutilized regions and propose optimization strategies.
The thesis will leverage SuperMUC-NG Phase 2, equipped with Intel Ponte Vecchio (PVC) GPUs capable of training models from 3B up to 175B parameters, as well as additional LRZ testbeds. You will conduct multinode experiments spanning hundreds of nodes and more than hundreds GPUs, enabling measurements and analyses that reflect the realities of modern foundation-model training. This environment supports systematic exploration of scaling behaviour, performance limits, and optimization strategies across architectures, hardware platforms, and distributed training configurations.
contact: ajay.navilarekal@lrz.de
The AI landscape has been transformed by foundation models that can be adapted for diverse tasks. Evidence increasingly shows a clear relationship between model scale and capability, systems with hundreds of billions of parameters consistently achieve superior results compared to their more compact alternatives. However, this scalability advantage introduces substantial practical barriers. The computational demands of training such massive neural networks require sophisticated infrastructure and careful resource management, making efficient training strategies essential for advancing the field.
Distributed Asynchronous Object Storage (DAOS) is an open-source software-defined high-performance scalable storage system that has redefined performance for a wide spectrum of AI and HPC workloads. In this thesis you will characterize and optimize I/O operations on DAOS during distributed LLM training and measure checkpoint bandwidth, latency, and parallel file system contention. You analyze how I/O overhead scales with the number of nodes and model size and compare checkpointing strategies (sharded, streamed, asynchronous, compressed). and propose methods to reduce checkpoint-induced disruptions during multinode runs.
The thesis will leverage SuperMUC-NG Phase 2, equipped with Intel Ponte Vecchio (PVC) GPUs capable of training models from 3B up to 175B parameters, as well as additional LRZ testbeds. You will conduct multinode experiments spanning hundreds of nodes and more than hundreds GPUs, enabling measurements and analyses that reflect the realities of modern foundation-model training. This environment supports systematic exploration of scaling behaviour, performance limits, and optimization strategies across architectures, hardware platforms, and distributed training configurations.
contact: ajay.navilarekal@lrz.de
The AI landscape has been transformed by foundation models that can be adapted for diverse tasks. Evidence increasingly shows a clear relationship between model scale and capability, systems with hundreds of billions of parameters consistently achieve superior results compared to their more compact alternatives. However, this scalability advantage introduces substantial practical barriers. The computational demands of training such massive neural networks require sophisticated infrastructure and careful resource management, making efficient training strategies essential for advancing the field.
In this work, you develop models of energy use for large-scale, multinode training pipelines, track energy per iteration, per FLOP, and per GPU across distributed configurations for different model sizes, study effects of mixed precision, communication intensity, and batch size, identify energy-efficient operating points for large LLMs. and explore scaling laws relating model size, throughput, communication cost, and power consumption.
The thesis will leverage SuperMUC-NG Phase 2, equipped with Intel Ponte Vecchio (PVC) GPUs capable of training models from 3B up to 175B parameters, as well as additional LRZ testbeds. You will conduct multinode experiments spanning hundreds of nodes and more than hundreds GPUs, enabling measurements and analyses that reflect the realities of modern foundation-model training. This environment supports systematic exploration of scaling behaviour, performance limits, and optimization strategies across architectures, hardware platforms, and distributed training configurations.
contact: ajay.navilarekal@lrz.de
The AI landscape has been transformed by foundation models that can be adapted for diverse tasks. Evidence increasingly shows a clear relationship between model scale and capability, systems with hundreds of billions of parameters consistently achieve superior results compared to their more compact alternatives. However, this scalability advantage introduces substantial practical barriers. The computational demands of training such massive neural networks require sophisticated infrastructure and careful resource management, making efficient training strategies essential for advancing the field.
In this work you will…
- Analyze and improve throughput for full multinode training on SuperMUC-NG Phase 2
- Profile data pipelines, CPU–GPU transfers, and distributed compute stages
- Evaluate sensitivity to parallelism strategies (DP, TP, PP), cluster topology, and interconnect bandwidth
- Identify pipeline stalls and communication bottlenecks that intensify at large scale
- Propose system-level or software-level optimizations to improve scaling efficiency.
The thesis will leverage SuperMUC-NG Phase 2, equipped with Intel Ponte Vecchio (PVC) GPUs capable of training models from 3B up to 175B parameters, as well as additional LRZ testbeds. You will conduct multinode experiments spanning hundreds of nodes and more than hundreds GPUs, enabling measurements and analyses that reflect the realities of modern foundation-model training. This environment supports systematic exploration of scaling behaviour, performance limits, and optimization strategies across architectures, hardware platforms, and distributed training configurations.
contact: ajay.navilarekal@lrz.de
Benchmarking of (Industrial-) IoT & Message-Oriented Middleware

DDS (Data Distribution Service) is a message-oriented middleware standard that is being evaluated at the chair. We develop and maintain DDS-Perf, a cross-vendor benchmarking tool. As part of this work, several open theses regarding DDS and/or benchmarking in general are currently available. This work is part of an industry cooperation with Siemens.
Please see the following page for currently open positions here.
Note: If you are conducting industry or academic research on DDS and are interested in collaborations, please see check the open positions above or contact Vincent Bode directly.
Applied mathematics & high-performance computing

There are various topics available in the area bridging applied mathematics and high-performance computing. Please note that this will be supervised externally by Prof. Dr. Martin Schreiber (a former member of this chair, now at Université Grenoble Alpes).
This is just a selection of some topics to give some inspiration:
(MA=Master in Math/CS, CSE=Comput. Sc. and Engin.)
- HPC tools:
- Automated Application Performance Characteristics Extraction
- Portable performance assessment for programs with flat performance profile, BA, MA, CSE
- Projects targeting Weather (and climate) forecasting
- Implementation and performance assessment of ML-SDC/PFASST in OpenIFS (collaboration with the European Center for Medium-Range Weather Forecast), CSE, MA
- Efficient realization of fast Associated Legendre transformations on GPUs (collaboration with the European Center for Medium-Range Weather Forecast), CSE, MA
- Fast exponential and implicit time integration, BA, MA, CSE
- MPI parallelization for the SWEET research software, MA, CSE
- Semi-Lagrangian methods with Parareal, CSE, MA
- Non-interpolating Semi-Lagrangian Schemes, CSE, MA
- Time-splitting methods for exponential integrators, CSE, MA
- Machine learning for non-linear time integration, CSE, MA
-
Exponential integrators and higher-order Semi-Lagrangian methods
- Ocean simulations:
- Porting the NEMO ocean simulation framework to GPUs with a source-to-source compiler
- Porting the Croco ocean simulation framework to GPUs with a source-to-source compiler
- Health science project: Biological parameter optimization
- Extending a domain-specific language with time integration methods
- Performance assessment and improvements for different hardware backends (GPUs / FPGAs / CPUs)
If you're interested in any of these projects or if you search for projects in this area, please drop me an Email for further information
HPC for Ocean modeling
Background:
This topic is working on a part of a a source-to-source compiler to automatically parallelize and optimize ocean models for modern HPC infrastructure. One important part of this is improving node-to-node communication as this is often a performance bottleneck. One approach to this is using asynchronous communication and overlapping communication and computation, such that the network can communicate in the background while the CPU is doing independent computation. There are multiple different strategies how to split communication and computation to make this possible with the given data dependencies.
We want to explore how these strategies affect the model performance under different conditions (problem size, hardware, etc.).
Tasks:
- Implementing code generation for one or multiple overlap strategies
- Identifying and setting up test cases and configurations to evaluate the strategies' correctness and performance
- Evaluating the effects of the strategies on the performance for different configurations
Contact:
Anna Mittermair (anna.mittermair@tum.de)
Background:
This topic is working on a part of a a source-to-source compiler to automatically parallelize and optimize ocean models for modern HPC infrastructure. One important part of this is improving node-to-node communication as this is often a performance bottleneck. This is done using transformations of a data-flow graph representing the code.
The goal of this thesis is to provide testing and validation for this part of the compiler, evaluating if given graph transformations and their sub steps, or given communication methods are formally correct.
Tasks:
- Formalize graph transformation rules for the given code and use case
- Create tests (using Python) to validate that a given transformation is valid according to the rules
- Come up with a minimal but sufficient set of test cases for testing code correctness
Contact:
Anna Mittermair (anna.mittermair@tum.de)
Background:
This topic is working on a part of a a source-to-source compiler to automatically parallelize and optimize ocean models for modern HPC infrastructure. One important part of this is improving node-to-node communication as this is often a performance bottleneck. One approach to this is using asynchronous communication and overlapping communication and computation, such that the network can communicate in the background while the CPU is doing independent computation.
In this case, the order in which different operations (communication or computation) are arranged in the generated code and then executed affects the potential for overlap and therefore on the communication performance. This depends of factors such as arithmetic and memory intensity of the code, problem size, message size, factors related to the communication library (we use MPI), the network etc. The goal of the thesis is to model and explore this.
Tasks:
- Implement algorithms to generate different orders
- Create a model to predict the communication performance for a given order
- Benchmark the generated code to evaluate the model
Contact:
Anna Mittermair (anna.mittermair@tum.de)
AI or Deep Learning Related Topics
Rapid advancement of machine learning (ML) has opened new frontiers in understanding and modeling complex fluid dynamics phenomena. Fluid dynamics, governed by the Navier-Stokes equations, underpins a wide range of applications, from weather forecasting and aerodynamics to energy systems and biomedicine. However, the inherent non-linearity and high-dimensional nature of these problems present challenges for traditional numerical solvers, particularly in scenarios that require large-scale simulations.
Multi-GPU training and scaling are crucial for modern machine learning because models and datasets are growing rapidly in size and complexity. Training a large neural network on a single GPU can take days, limiting both productivity and experimentation. By distributing computation across multiple GPUs, training becomes significantly faster, enabling faster iteration cycles and reducing time-to-result. Scaling also makes it possible to train models that exceed the memory capacity of a single GPU, unlocking the ability to handle larger batch sizes and higher resolution data. For both research and real-world applications, efficient multi-GPU training is essential to push the boundaries of model performance while keeping computational costs and development timelines manageable.
In this work, we try to scale up the current implementation of an existing training pipeline which has interesting SOTA models such as Transformers, Neural operators etc. to multi-GPUs and potentially to multinode training.
Milestones:
- Understand the existing pipeline, which is mainly based on the HuggingFace trainer class.
- Try out the built-in multi-GPU implementation from HuggingFace and discover potential bugs.
- Benchmark performance on multi-GPUs
Requirements:
- Experience with Python (esp. Pytorch) and Parallel Programming is a must.
- Familiarity with HuggingFace transformers library is a plus.
- Some knowledge of machine learning.
- Ability to work independently.
Please note that this project shall be conducted in collaboration with TUM Chair of Aerodynamics and Fluid Mechanics.
Contact: Urvij Saroliya (urvij.saroliya@tum.de) and Harish Ramachandran (harish.ramachandran@tum.de) with the subject “Scaling SciML models”.
Please also attach your CV, current grade report, and link to Github (if worked on any open-source projects).
If you have interests regarding the following topics, and would like to know how to implement efficient AI or how to implement AI on different hardware setups, such as:
- DL Application on Heteragenous system
- Network Compression
- ML and Architecture
- AI for Quantum
- AI on Hardware (e.g. restricted edge devices, Cerebras)
Please feel free to contact dai.liu@tum.de for MA, BA, GR.
Compiler & Language Tools
Background & Context
Most of the energy efficiency projects in heterogeneous High Performance Computing (HPC) focus on run-time informed, post-mortem optimizations. While this approach is effective, it requires at least one execution on an application to collect the required input for the optimisations and another run to actually benefit from an optimised execution of an application.
Within the broader context of this project, we focus on a static, compile-time informed, pre-executional optimisations. We aim to implement a compiler pass that is able to optimise for energy rather than for performance during the compilation process. In addition to this compile-time optimisation, we want to lift an application that has not seen this energy compiler pass during its compilation process from its binary representation into LLVM Intermediate Representation (IR) and shift it into an energy-optimised state by applying the energy optimisation on the lifted application.
With this approach, we are able to optimise the energy consumption of an application without needing developers to change their codes or system administrators to change the settings of their HPC systems.
Goals & Expected Outcomes
The goal of this work is to Implement a tool that takes a fully compiled binary of a heterogeneous application and reverse compiles it into LLVM IR.
The framework should be able to reverse compile heterogeneous applications written for NVIDIA and AMD GPUs (scope depending on the thesis type).
Perspectively, this framework shall be extendable to deal with other acceleration that rely on the LLVM compiler suite.
Prerequisites
- Experience in low level programming languages (assembly, C/++)
- Interest and/ or experience in compiler technologies, especially with the LLVM compiler suite
Contact
Karlo Kraljic (karlo.kraljic@tum.de)


Created in the 1950s Fortran is still the prevailing language in many high-performance computing applications today. Most of the quantum chemistry codes that form the foundations of modern materials science are written in Fortran and it is not realistically feasible to rewrite these massive and complex computer programs in another language. In light of today’s advances in software development Fortran might be viewed as a dinosaur, but the language has a rich history and inspired many of the programming paradigms that we take for granted today. In more recent iterations of Fortran’s standardization process features were added to bring the language more on par with the current ways to develop software, such as object oriented programming [1]. One consequence of Fortran having fallen out of fashion for contemporary projects is that the available compilers and associated tooling do not get exercised to the extent of more popular general purpose programming languages such as C or C++. To this end we offer three Bachelor thesis projects that deal with Fortran compiler technologies.
I. RANDOM PROGRAM GENERATION TO DETECT FORTRAN COMPILER BUGS
Due to the limited use there are often subtle bugs present in various Fortran compiler implementations. Usually these are triggered accidentally in an existing large project which can be quite annoying as it will require workarounds or even prohibit the use of certain language features until the bug is fixed upstream. This issue naturally does not only plague Fortran compilers, but C and C++ compilers are equally affected. To this end an interesting approach was developed, named Random Program Generation. A tool generates a random but valid program that is fully standard conforming, i.e., does not invoke undefined or unspecified behavior. In the first stage, the generated program is then compiled to see whether it crashes the compiler under investigation. When that is successful, the program is compiled by another (ideally known good) compiler and the two binaries are executed to understand whether there is any observable difference in runtime behavior. If either of these two stages is unsuccessful, there is a compiler bug that needs to be reported and fixed by the compiler developers. The approach of random program generation is supposed to preempt the accidental discovery of compiler bugs during project development. In this thesis we will implement random program generator for the Fortran programming language informed by the prior work on Csmith [2] and YARPGen [3] for the C and C++ programming languages. This tool will allow us to more comprehensively test Fortran compilers for bugs that we normally encounter during our in-house development of electronic structure and plasma physics codes. We offer an interesting hands-on project that deals with the fundamentals of a well-established programming language and potentially the inner workings of several industry-standard compilers and thereby teaches important transferable skills. A collaboration with Advanced Micro Devices, Inc. (AMD) is conceivable. The ideal candidate has a good knowledge of compiler construction and a strong background in concepts of programming languages, ideally with good knowledge of C++ as well as some basic familiarity with Fortran.
II. FORTRAN PROGRAM REDUCER FOR DELTA DEBUGGING
When compiler bugs are accidentally triggered during development of an existing large project, it is often difficult to clearly isolate the offending statements into a minimal exmaple. Justifiably, compiler maintainers demand minimal examples, because it is not a good use of time to sift through the masses of abstract syntax trees, intermediate representations and generated machine code instructions that are generated by a large project. To this end a technique commonly referred to as test case reduction was developed. At the start a so-called “interestingness test” must be formulated which indicates whether its input does reproduce the desired error, i.e. it is interesting, and should be refined further. In the na¨ıvest form the refinement randomly discards lines, words, or characters and from the input file and applies the interestingness test repeatedly. This leads to poor convergence behavior towards a minimal example, because randomly deleting elements from the input file, generally results in invalid programs. A much more promising approach is to delete elements in a way that is informed by the semantic analysis of the input program to efficiently remove dead code and resolve dependencies. Such an approach was previously realised for C/C++ under the name C-Reduce [4] and its successor CVise. The LLVM Project is a collection of modular and reusable compiler and toolchain technologies [5]. The C-Reduce and CVise program reducers for C/C++ internally rely on a helper program called clang delta based on the LLVM Clang C/C++ compiler to perform the guided reduction of programs mentioned above. LLVM also ships with a Fortran compiler named Flang [6], which is currently under active development, but is already being used in production as the basis for the AMD Optimizing C/C++ and Fortran Compilers (AOCC). At the moment there does not exist a flang delta program. In this thesis we will implement a flang delta program based on LLVM Flang. This tool will allow us to more effectively reduce programs that trigger compiler bugs that we find during our in-house development of electronic structure codes. We offer an interesting hands-on project that deals with the inner workings of one of the most advanced industry-standard compilers and thereby teaches important transferable skills. A collaboration with Advanced Micro Devices, Inc. (AMD) is conceivable. The ideal candidate has a good knowledge of compiler construction and a strong background in concepts of programming languages, ideally with excellent knowledge of C++, exprience with Python and Perl, as well as some basic familiarity with Fortran.
III. AUTOMATIC PYTHON INTERFACE GENERATION FOR FORTRAN LIBRARIES
Probably the most used programming language in contemporary computational science is Python. Its expressive, highly readable syntax combined with dynamic typing and a rich ecosystem for numerical methods are key enablers for its popularity. However, Python itself being an interpreted language is slow and not well-suited for high-performance computing by itself. This is why many libraries such as NumPy or SciPy are implemented in C/C++/Fortran with an interface leveraging the Python/C API to expose the desired functionality to the Python scripting language. Two main approaches exist to interface low-level code with Python. The first is to directly write Python/C API calls into the library or do so via a wrapper such as pybind11 or nanobind. While this offers the greatest amount of flexibility, it also comes with a high development cost, due to interfaces having to be constructed manually. The other approach is to parse the source code of the library and then programmatically generate the required interface code. This is the approach taken by NumPy and SciPy which both use their own tool F2PY [7] to perform the wrapping. However, F2PY is fairly limited in what Fortran language features it supports and is also not really intended for use outside of NumPy/SciPy. A similar tool for the C/C++ programming languages is SWIG [8] which also supports a large varieties of other programming and scripting languages to generate interfaces for. The LLVM Project is a collection of modular and reusable compiler and toolchain technologies [5]. As an alternative to SWIG there exists a tool called Clair (Clang Introspection and Reflection tools) [9], developed by the Flatiron Institute in New York, USA, that also parses the C++ code and generates interfaces, but in contrast to SWIG leverages LLVM for the parsing. LLVM also ships with a Fortran compiler named Flang [6], which is currently under active development, but is already being used in production as the basis for the AMD Optimizing C/C++ and Fortran Compilers (AOCC). In this thesis we will extent Clair to generate Python interfaces for Fortran code based on LLVM Flang. This tool will allow us to easily generate Python interfaces for a number of high-performance applications with focus on the Octopus electronic structure code. We offer an interesting hands-on project that deals with the inner workings of one of the most advanced industry-standard compilers and thereby teaches important transferable skills. A collaboration with the Center for Computational Quantum Physics (CCQ) of the Flatiron Institute in New York, USA is conceivable. The ideal candidate has a good knowledge of compiler construction and a strong background in concepts of programming languages, ideally with excellent knowledge of C++ and some basic familiarity with Fortran.
[1] J. Reid, The new features of Fortran 2018, ACM SIGPLAN Fortran Forum 37, 5 (2018).
[2] X. Yang, Y. Chen, E. Eide, and J. Regehr, Finding and understanding bugs in C compilers, ACM SIGPLAN Notices 46, 283–294 (2011).
[3] V. Livinskii, D. Babokin, and J. Regehr, Random testing for C and C++ compilers with YARPGen, Proceedings of the ACM on Programming Languages 4, 1–25 (2020).
[4] J. Regehr, Y. Chen, P. Cuoq, E. Eide, C. Ellison, and X. Yang, Test-case reduction for C compiler bugs, ACM SIGPLAN Notices 47, 335–346 (2012).
[5] C. Lattner and V. Adve, LLVM: A compilation framework for lifelong program analysis & transformation, in International Symposium on Code Generation and Optimization, 2004. CGO 2004. (IEEE).
[6] flang.llvm.org.
[7] P. Peterson, F2PY: a tool for connecting Fortran and Python programs, International Journal of Computational Science and Engineering 4, 296–305 (2009).
[8] D. M. Beazley et al., SWIG : An easy to use tool for integrating scripting languages with C and C++, in Tcl/Tk Workshop, Vol. 43 (1996) p. 74.
[9] github.com/flatironinstitute/clair.
Contact: henri.menke@mpcdf.mpg.de