The COD group is working on coding and information theory and its applications. Our research considers code constructions, decoding algorithms, and combinatorial properties. We deal with classical codes such as Reed-Solomon and BCH codes, as well as with coding in other metrics, e.g., the rank metric, the cover metric, and the Levenshtein metric. Further, we investigate information-theoretic properties of various setups in our research fields.
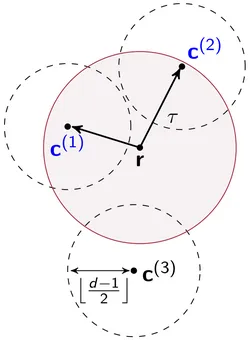
One aspect of our work is list decoding which is a powerful technique for increasing the error correcting capability of codes. A list decoder returns not only a unique decoding result, but all codewords in a certain radius around the received word. In pratical applications, list decoding is frequently used in concatenated coding schemes.
Currently working in this area:
- Anisha Banerjee
- Jessica Bariffi
- Anna Baumeister
- Sebastian Bitzer
- Maximilian Egger
- Christoph Hofmeister
- Luis Maßny
- Vivian Papadopoulou
- Anmoal Porwal
- Stefan Ritterhoff
- Hugo Sauerbier Couvée
- Bharath Purtipli
- Frederik Walter
- Marvin Xhemrishi
- Hrishi Narayanan
- Rawad Bitar
- Antonia Wachter-Zeh

The realistic threat of a quantum supercomputer has motivated research on post-quantum cryptography. Assuming an attack of a sufficiently large quantum computer, several classical public-key algorithms as RSA become insecure since computationally intensive mathematical problems become easy-to-solve. It is therefore necessary to design techniques which are secure against an attack of a quantum computer. One approach to achieve this security is code-based cryptography, where encryption and decryption is based on encoding and decoding an algebraic code. The COD group investigates and improves post-quantum cryptographic systems, also including lattice-based and code-based homomorphic encryption schemes. Other security-related topics of our group include physical unclonable functions.
Currently working in this area:
- Anna Baumeister
- Sebastian Bitzer
- Gökberk Erdogan
- Emma Munisamy
- Anmoal Porwal
- Stefan Ritterhoff
- Hugo Sauerbier Couvée
- Bharath Purtipli
- Antonia Wachter-Zeh
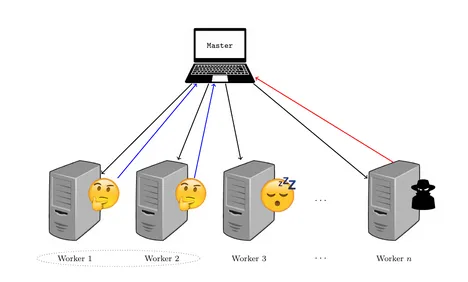
In distributed computing, the master is interested in computing complex tasks, which can be done by hiring external workers and splitting the computation into smaller tasks. The tasks are distributed to the workers that can run the computation in parallel, i.e., independent from each other. However, the presence of slow processing nodes, known as stragglers, can outweigh the benefits of parallelism. Moreover, the data involved into computation can be sensitive, in the sense that its leak can harm the owner. Thus, private and secure coded computation uses coding theory techniques to guarantee privacy against a group of workers that share information among each other to extract information about the dataset, secrecy against adversarial workers that try to affect the computation in their behalf and resiliency against straggler nodes.
Currently working in this area:
- Maximilian Egger
- Christoph Hofmeister
- Luis Maßny
- Vivian Papadopoulou
- Marvin Xhemrishi
- Rawad Bitar
- Antonia Wachter-Zeh
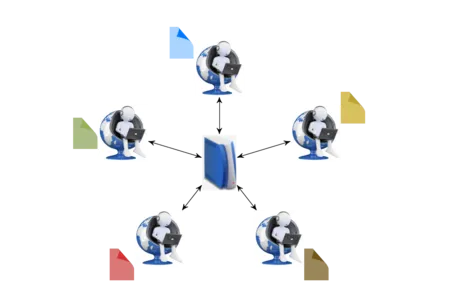
In federated learning, a collection of users wants to collaboratively train a machine learning algorithm based on their local data with the help of a central coordinator, called federator. Solving this problem amounts to running a distributed optimization problem, i.e., distributed stochastic gradient descent. The main challenges of federated learning are maintaining the privacy of the users’ individual data, ensuring robustness against malicious users that deliberately try to corrupt the process, tolerating users that dropout of the system during the process, and efficiently communicating and using the users’ computations. However, extra care must be taken to tackle the challenges mentioned above. For example, tolerating dropouts is crucial to prevent bias in the learning process as the users store heterogenous (individual) data.
Coding and information theoretic techniques are used to ensure privacy of the users’ data, tolerate dropouts, and efficiently aggregate the partial gradients at the federator. In addition, statistics on the users’ calculations are used to mitigate the negative impacts of malicious nodes and their corrupt computations. Furthermore, gradient compression techniques serve to reduce the communication load between the users and the federator while retaining fast convergence of the optimization algorithm.
Currently working in this area:
- Maximilian Egger
- Christoph Hofmeister
- Luis Maßny
- Vivian Papadopoulou
- Marvin Xhemrishi
- Hrishi Narayanan
- Rawad Bitar
- Antonia Wachter-Zeh
Data Storage in synthesized DNA is a novel approach for long-term data storage motivated by the high storage density and durability. Due to biological processes this requires codes that correct special errors such as insertions, deletions, duplications and other errors.
Currently working in this area:
- Anisha Banerjee
- Jessica Bariffi
- Frederik Walter
- Hrishi Narayanan
- Rawad Bitar
- Antonia Wachter-Zeh

Data storage media like flash memories (used in USB flash drives or solid state drives) suffer from manufacturing imperfections, wearout, and fluctuating read/write errors. In cloud storage systems with distributed data storage, it is necessary to design coding solutions in order to cope with failures of data servers.
Further, data retrieval from a data base shared by many users is a common occurrence in online services (e.g., Netflix, YouTube,...). Privacy protection regulations pose new challenges for providers of such services. Private Information Retrieval offers coding solutions that hide the identity of the file a user desires, while minimizing the communication overhead.
Currently working in this area:
- Rawad Bitar
- Antonia Wachter-Zeh
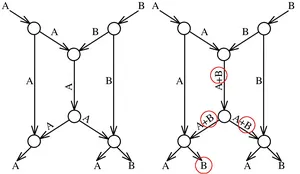
The principle of network coding has been attracting growing attention in the recent years as a technique to disseminate information in data networks, due to the higher achievable throughput compared to routing. In routing, the packets are forwarded at each node of the network, whereas in (linear) network coding, the nodes perform linear combinations of all packets received so far. Fundamental questions in the area of network coding include assigning appropriate linear combinations to the nodes and choosing a suitable error-correcting code for the case when packets are lost or adversaries inject erroneous packets.
Currently working in this area:
- Antonia Wachter-Zeh
Funding Organizations and Research Projects
The COD group receives funding from the following organizations within the scope of several research projects.
Deutsche Forschungsgemeinschaft (DFG)
DFG Middle-East Project, “Fundamentals of Coding and Information Theory for Edit Errors”
PIs: Rawad Bitar, Antonia Wachter-Zeh, Eitan Yaakobi
ANR-DFG Project, “CROWD: Cryptography with Skew Codes”
PIs: Delphine Boucher, Pierre Loidreau (French coordinator), Felix Ulmer, Annelie Heuser, Juliane Krämer, Antonia Wachter-Zeh (German coordinator)
DFG Project, “Coded Distributed Computation with Application to Machine Learning”
PI: Antonia Wachter-Zeh
European Innovation Council (EIC)
EU Pathfinder Challenges, Horizon Europe, “DiDAX: DNA Data Applications”
PIs: Zohar Yakhini, Eitan Yaakobi, Reinhard Heckel, Marc Somoza, Robert Grass, Antonia Wachter-Zeh
Cyberagentur
Encrypted Computing, “PQ-PRIME: Post-Quantum Privacy by Homomorphic Encryption”
PIs: Hannes Bartz, Antonia Wachter-Zeh
Federal Ministry of Research, Technology and Space (BMFTR)
ITS-Post-Quanten-Kryptografie - Anwendungen, “Post-Quanten-sichere Public-Key-Infrastruktur (PKI) für die Cloud-Anbindung in kritischen Infrastrukturen”
Project partners: RPTU, KSB, TUM (Georg Sigl, Antonia Wachter-Zeh), SSV, Thales
6G Life
Main PIs: Holger Boche, Wolfgang Kellerer
Bavarian Ministry of Economic Affairs, Regional Development and Energy (StMWi)
6G Future Lab Bavaria
Main PI: Wolfgang Kellerer
International Graduate School of Science and Engineering (IGSSE)
TUM-ICL IGSSE JADS Project, “Coded Computation for Large Scale Machine Learning with Privacy Guarantees”
PIs: Deniz Gunduz (ICL), Antonia Wachter-Zeh
Industry Partners
