Neural Networks and Accelerators
Researchers: Chuangtao Chen, Sijie Fei, Richard Petri, Zhuorui Zhao, Kangwei Xu, Guanyu Chi, Ruidi Qiu, Bo Liu, Tarik Ibrahimpasic, Amro Eldebiky, Wenhao Sun
We are offering reserach topics in the following categories:
- Hardware accelerators based on digital logic and emerging devices for deep neural networks
- Neural network architectures
- Security of computing hardware and neural networks
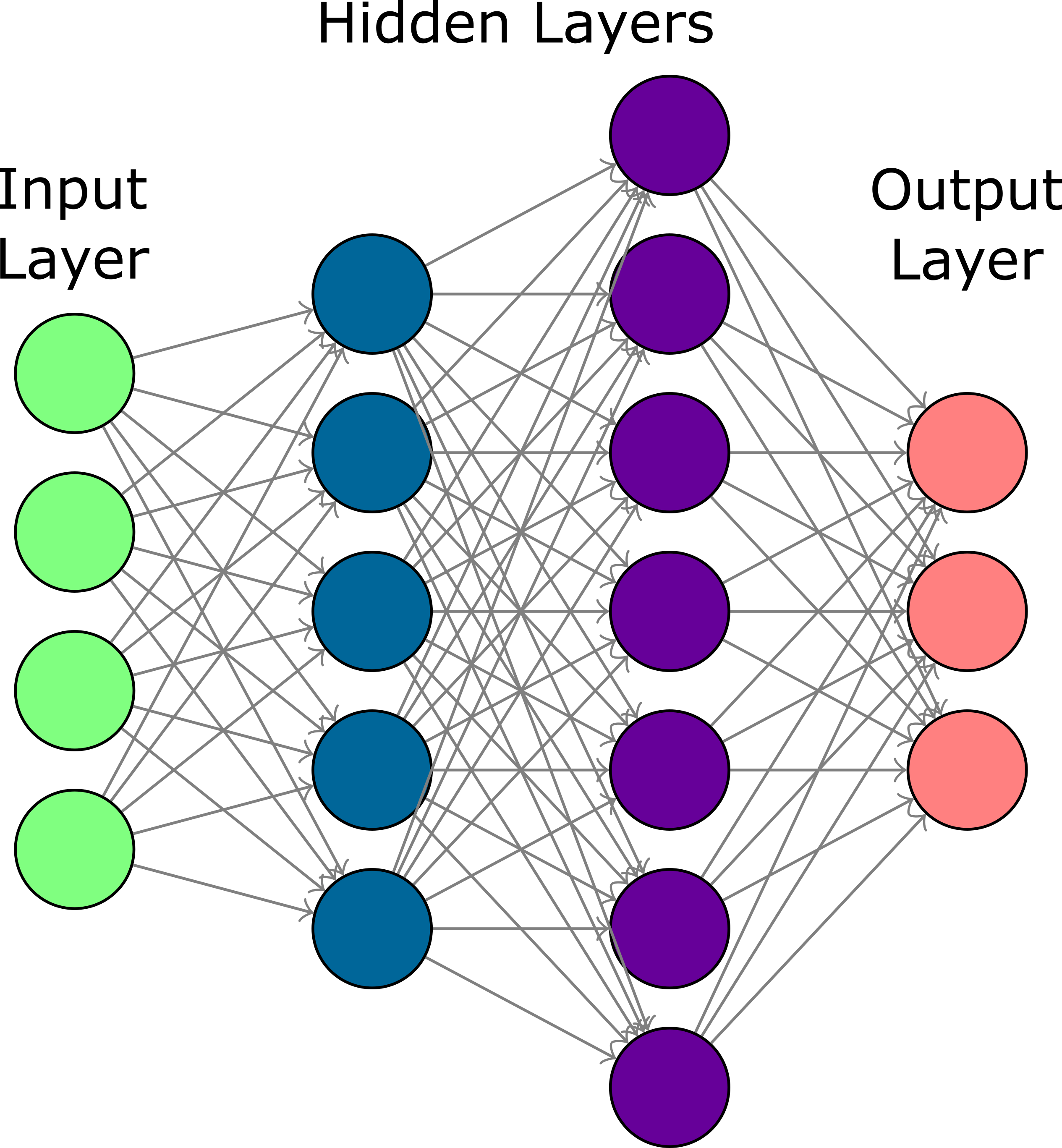
Machine learning and neural networks have successfully been applied to solve complex problems such as speech/image processing. To improve computing accuracy, the depth of neural networks has steadily increased significantly, leading to deep neural networks (DNNs). The increasing complexity has put massive demands on computing power and triggered intensive research on hardware acceleration for neuromorphic computing in recent years. To accelerate DNNs, we are exploring solutions based on digital logic, resistive RAM (RRAM), and silicon photonic components. Our research covers novel neural network architectures, efficient mapping of computation operations in DNNs onto hardware accelerators, high-performance and low-power hardware design, and security of computing hardware as well as neural networks.
Digital circuits for accelerating neural networks

In DNNs, the number of required multiply-and-accumulate operations explodes to an extremely huge quantity that resource-constrained platforms cannot afford executing within an acceptable time. To accelerate these operations in DNNs, digital architectures such as systolic array deployed in TPUs have become attractive solutions due to their high degree of concurrent computation and high data reuse rate. In such architectures, weights are first fetched into the processing elements (PEs), and then the input data are streamed into the systolic array, similar to deep pipelining in digital design. To enhance the computation efficiency further, weight pruning has also been developed to compress neural networks without sacrificing accuracy noticeably. This compression takes advantage of the inherent redundancy and flexibility of neural networks, in which a large portion of weights can actually be omitted during the computation. Combining these approaches, we are investigating efficient digital hardware for accelerating neural networks, majorly focusing on circuit architectures, power efficiency, as well as FPGA-based reconfigurable computing.
RRAM-based Neuromorphic Computing
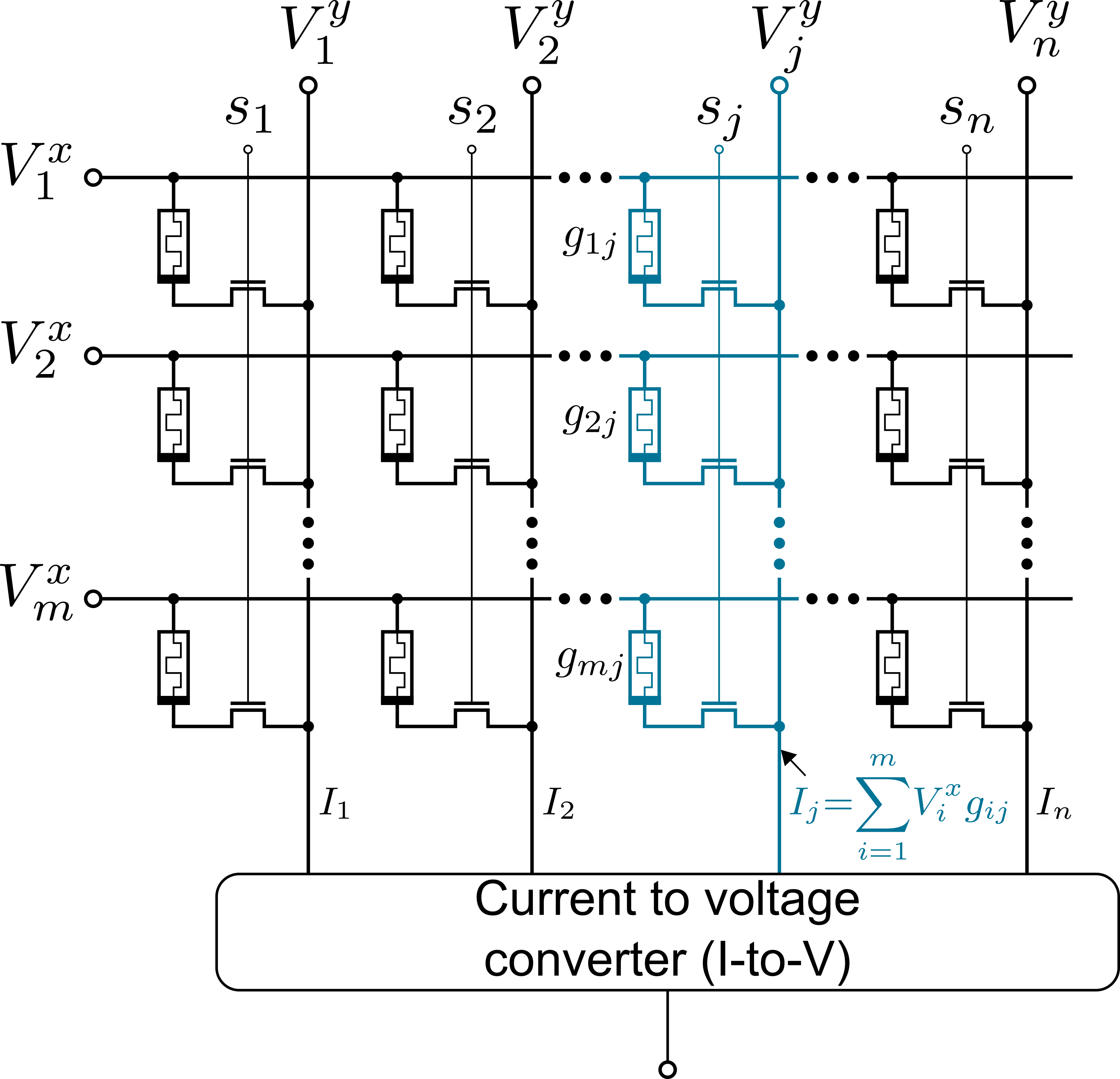
As a promising emerging nonvolatile memory technology, RRAM has been explored intensively for accelerating neuromorphic computing. In such an accelerator, RRAM cells sit at the crossing points of the horizontal wordlines and the vertical bitlines of a crossbar. Multiply operations are implemented by individual RRAM cells according to Ohm’s law, and accumulate operations are implemented by the aggregation of currents according to Kirchhoff’s law. By storing weights of neural networks in memory units and allowing them to participate in computation directly, such in-memory-computing accelerators can overcome the memory bottleneck in the traditional von Neumann architecture. Even more importantly, they exploit the analog nature of the underlying devices to realize the multiply-and-accumulate operations, thus achieving a very high performance and power efficiency. However, due to the analog nature, this computing scheme is very sensitive to hardware uncertainties such as process variations, temperature and noise. To deal with these challenges, we are developing a framework to enhance the robustness and reliability of RRAM-based computing platforms with co-design approaches.
Optical Accelerators for Neural Networks
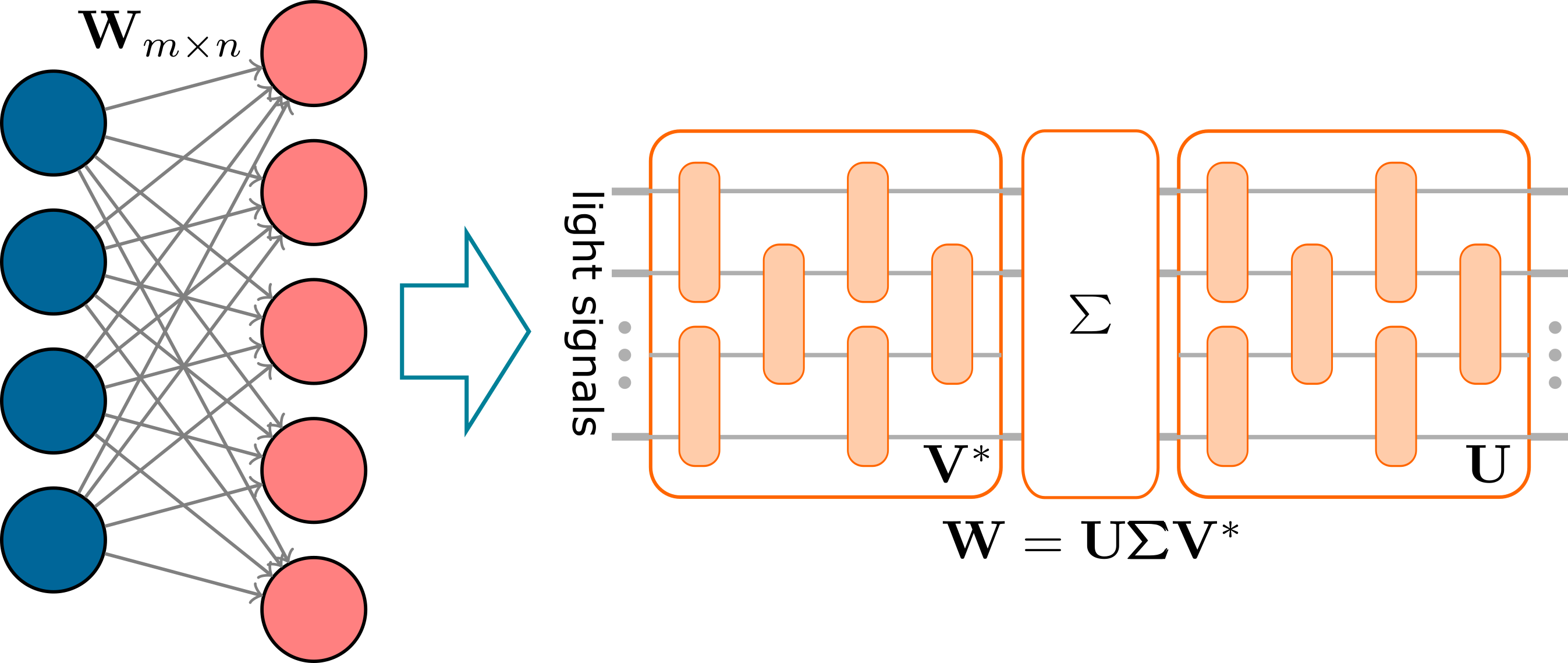
Optical accelerators for neural networks are implemented with silicon photonic components such as Mach-Zehnder Interferometers (MZIs) and use light as the computation media. On the one hand, data propagation inside optical computing units happens at the speed of light. On the other hand, properties of light signals such as phases can be modulated efficiently with a very low power consumption to implement computing functions. Accordingly, computing with light has a large potential to offer high performance and high power efficiency simultaneously. In implementing matrix-vector multiplication operations in neural networks by optical accelerators, the weight matrices need to be decomposed, leading to a rapid increase of the optical components. In addition, hardware uncertainties also affect the computation accuracy severely. To address these problems, we are exploring new architectures of optical accelerators that can offer high performance, robustness, and hardware efficiency simultaneously.