PASSTA
PASSTA (IPC and Synchronizing Shared data on heterogeneous MPSoCs) is a project in cooperation with Huawei focusing on assisting traditional Operating System services with hardware. Currently, we investigate Inter-Process Communication (IPC) mechanisms in Linux and plan to extend the developed concepts further to applocations within micro-kernels.
IPC is a general term for mechanisms used to communicate amongst different processes. This communication can be used for data transfer, synchronization, or both. Traditionally, IPC functionalities are tightly integrated into the Operating System as they are highly critical for achieving good throughputs and latencies. The ongoing development towards heterogeneous multi-/many-core processor architectures exposes performance insufficiencies in established IPC services. An increasing number of CPUs and more fine-grained multi-threaded/-process applications lead to more dependencies and data exchange between different application parts, utilizing IPC services to synchronize accesses to the same dataset. The ever-increasing utilization of IPC mechanisms highlights these insufficiencies, which impact the applications' performance.
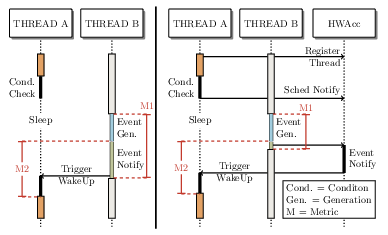
When multiple threads interact, scenarios can occur where a thread must wait for a certain condition before continuing its execution. For instance, such a condition may be a free lock or the availability of data. An event can be considered as a state change of this condition and can be triggered by different sources such as device drivers, communication channels or interacting threads. Event notification is used to inform that a particular event of interest has occurred. In PASSTA, we focus on blocking event notification mechanisms. In these mechanisms, the event-receiving thread calls a specific function to get new events. This function returns successfully if an event is available. Otherwise, this function puts the thread asleep, waiting for the corresponding condition to be met (blocking behavior). An event-generating thread has to notify the sleeping thread about a condition change and thus an occurred event by triggering its wake-up (event notification).
To improve this event notification we develop in PASSTA a concept to assist blocking IPC mechansisms with a hardware component (HWAcc). When improving event notification, two metrics have to considered:
- Metric 1 - Syscall duration: As depicted in the figure with M1, the syscall includes the event generation and the event notification that initiates the thread wake-up. The CPU cycles required for the syscall show the overhead that an event notification can add to a thread that generates an event.
- Metric 2 - Wake-up latency: This metric denotes the number of cycles for a thread wake-up initiation, and is labeled with M2 in the figure. For this, we measure the time from the start of the event notification function in thread B until thread A is active. As the HWAcc processes a request asynchronously, only metric 2 includes the execution time of the HWAcc itself.
Reduce burden for event-generating thread (Metric 1):
Thread A has to wait for a particular condition before it can continue its execution, e.g., if a lock is not available (Cond. Check). In Linux, to be notified about a change in this condition, a wait list is used to specify the expected notification when this event occurs. This wait list is filled by thread A before it goes to sleep. Notification of a sleeping thread is initiated by its wake-up. Many wait lists exist in the kernel, each tied to a certain element (e.g., a file descriptor), while the wait list structure is always the same. After thread B generates an event the condition becomes valid, e.g., if a lock is released (Event Gen.). Therefore thread B checks whether another thread was waiting for the event by querying the wait list, and to wake up thread A in the original event notification approach (Event Notify).
In PASSTA we developed a concept to facilitate the event notification by initiating the thread wake-up from a hardware unit (HWAcc), thus relieving the thread that generates an event. This can be achieved by replacing the default notification function in the wait list in step Cond. Check with one that offloads the wake-up initiation to the HWAcc. The HWAcc then asynchronously initiates a thread wake-up.
Reducing the latency in blocking IPC mechanisms (Metric 2):
Several steps are involved in the wake-up procedure triggered by an event-generating thread. First, the waker (thread B) determines which thread to wake up and where to wake it up. After that, an IRQ/IPI is sent to the core on which thread A should be woken up. On the wakee side in the interrupt service routine, the wakelist is checked, and consequently, the scheduler is triggered to determine whether the newly awakened thread A should run on the core. All these steps contribute to the latency of IPC and consist mainly of scheduling-related functions.
We aim to decrease the time spent in scheduling-related functions to reduce the latency of blocking IPC mechanisms. Therefore, we introduce a hardware-assisted scheduling class into Linux, which offloads scheduling functionalities to a dedicated hardware unit. This newly created scheduling class coexists with the standard scheduling classes, thus enabling a seamless integration into the Linux kernel.
Thesis Offers
Interested in an internship or a thesis? Please send us (Tim Twardzik, Lars Nolte) an email.
The given type of work is just a guideline and could be changed if needed.
From time to time, there might be some work, that is not announced yet. Feel free to ask!
Ongoing Theses
Completed Theses
2025
Bachelorarbeiten
-
10.03.2025
Comparison of Existing Inter-Process Communication Mechanisms in Linux
Betreuer:Lars Nolte
Masterarbeiten
-
28.02.2025
Hardware-Assisted Event Notification for Packets Received at the NIC
Betreuer:Lars Nolte -
19.02.2025
Hardware-Accelerated Linux Kernel Tracing
Betreuer:Lars Nolte
Forschungspraxis (Research Internships)
-
13.03.2025
Implementation of a FPGA-based Intersatellite Network Switch for High-Speed Traffic
Betreuer:Lars Nolte, Michael Hanh (Airbus)
2024
Bachelorarbeiten
-
30.08.2024
Developement and Evaluation of a Hardware Thread Scheduler on a FPGA
Betreuer:Tim Twardzik -
24.01.2024
Interprocess Communication: Signal events in user space with ueventfd and upipe
Betreuer:Lars Nolte
Forschungspraxis (Research Internships)
-
15.02.2024
Multithreaded UDP Server und Parser für Tracing Daten in Rust
Betreuer:Lars Nolte
Interdisziplinäre Projekte
-
17.07.2024
Development of a web application to control a hardware demonstration platform
Betreuer:Lars Nolte
2023
Bachelorarbeiten
-
30.10.2023
Nichtinvasives integriertes Event-Tracing von FPGA über Ethernet
Betreuer:Lars Nolte -
08.09.2023
Non intrusive hardware tracing over ethernet
Betreuer:Lars Nolte -
20.06.2023
Optimization of Hardware Assisted Futex Implementation on Zynq Ultrascale+
Betreuer:Lars Nolte -
20.03.2023 Maximilian Grözinger
Digital Design and Validation of Hardware Assisted Futex - Implementation on Zynq Ultrascale+
Betreuer:Lars Nolte -
03.03.2023
Analyzing Remote Procedure Calls in a Linux Environment
Betreuer:Tim Twardzik
Masterarbeiten
-
22.05.2023
Hardware-assisting the User-Epoll mechanism in Linux
Betreuer:Lars Nolte -
30.03.2023
Optimizing high-speed network packet processing in Linux
Betreuer:Lars Nolte
Forschungspraxis (Research Internships)
-
20.12.2023
Setting up L4Re on a Raspberry Pi
Betreuer:Lars Nolte -
13.06.2023
Analyzing Power Consumption in a Simulation Model
Betreuer:Tim Twardzik -
15.01.2023
Implementation of a Finite State Machine for Hardware Managed Futexes on Zynq Ultrascale+
Betreuer:Lars Nolte
Interdisziplinäre Projekte
-
17.03.2023
Exploring Hardware-Acceleration for the Linux Scheduler
Betreuer:Tim Twardzik -
17.03.2023
Exploring Hardware-Acceleration for the Linux Scheduler
Betreuer:Tim Twardzik
2022
Bachelorarbeiten
-
29.08.2022
Evaluating Asynchronous Communication Mechanisms in MPSoCs
Betreuer:Tim Twardzik -
09.03.2022
Reduction of the Simulation Time of the Gem5 Simulator
Betreuer:Lars Nolte
Masterarbeiten
-
20.12.2022
Entwicklung und Evaluierung eines Hardwarebeschleunigten Event Notifikations Mechanismus in Linux
Betreuer:Tim Twardzik -
13.12.2022
Digital Design and Validation of a Futex Hardware Accelerator – Emulation on Zynq Ultrascale+
Betreuer:Lars Nolte
Forschungspraxis (Research Internships)
-
30.09.2022
Cache Coherent Hardware Accelerator Integration into an ARM Multicore Platform with a FPGA extension
Betreuer:Lars Nolte -
01.07.2022
Entwicklung eund Evaluierung eines Hardware-beschleunigten IPC Mechanismuses
Betreuer:Tim Twardzik -
12.06.2022
Performance Improvement Evaluation of Hardware Accelerated Linux Thread Wake-ups
Betreuer:Lars Nolte
Seminare
-
20.07.2022
[MSEI] A survey on asynchronous event notification mechanisms in Linux systems.
Betreuer:Lars Nolte -
28.01.2022
Survey on Linux Scheduler and Options to tweak an Application’s Performance
Betreuer:Lars Nolte
Studentische Hilfskräfte
-
31.07.2022
Hardware Accelerator Integration into an ARM Multicore Platform with a FPGA extension
Betreuer:Lars Nolte
Interdisziplinäre Projekte
-
25.07.2022
Development of a Commmunication Library using Hardware-accelerated Inter-Process Communication
Betreuer:Tim Twardzik
2021
Bachelorarbeiten
-
01.12.2021
Integration of Performance Counter into a simulation model of a hardware accelerator in Gem5.
Betreuer:Lars Nolte -
22.09.2021
A Performance Analysis of the Linux Scheduler on ARM-based Systems
Betreuer:Tim Twardzik -
15.09.2021
Analysis of Semaphore IPC Mechanisms in Linux
Betreuer:Tim Twardzik -
13.09.2021
Setup of an ARM Multicore Platform with a FPGA extension using a Xilinx Zynq Board and a Linux OS.
Betreuer:Lars Nolte -
06.07.2021
Low-intrusive Software Tracing and Profiling using a Gem5 Simulator
Betreuer:Lars Nolte -
06.07.2021
Low-intrusive Software Tracing and Profiling using a Gem5 Simulator
Betreuer:Lars Nolte
Masterarbeiten
-
13.12.2021
Development of a Generic Framework for Linux Task Offloading to Hardware on a Multicore Architecture.
Betreuer:Lars Nolte -
13.12.2021
Development of a Generic Framework for Linux Task Offloading to Hardware on a Multicore Architecture.
Betreuer:Lars Nolte
Forschungspraxis (Research Internships)
-
20.12.2021
Conecpt for Hardware-supported Scheduling in Linux
Betreuer:Tim Twardzik -
15.12.2021
Processing Simulation based Tracing Information
Betreuer:Tim Twardzik -
12.05.2021
Continuous Integration set up for a Gem5 Simulator project
Betreuer:Lars Nolte
Publications
- HASIIL: Hardware-Assisted Scheduling to Improve IPC Latency in Linux. 21st ACM International Conference on Computing Frontiers, 2024 mehr… BibTeX Volltext ( DOI )
- HW-EPOLL: Hardware-Assisted User Space Event Notification for Epoll Syscall. International Conference on Embedded Computer Systems: Architectures, Modeling and Simulation 2024, 2024 mehr… BibTeX
- POSTER: Hardware Assist for Linux IPC on an FPGA Platform. 21st ACM International Conference on Computing Frontiers, 2024 mehr… BibTeX Volltext ( DOI )
- HW-FUTEX: Hardware-Assisted Futex Syscall. IEEE Transactions on Very Large Scale Integration Systems, 2023 mehr… BibTeX Volltext ( DOI )
- HAWEN: Hardware Accelerator for Thread Wake-Ups in Linux Event Notification. 2023 60th ACM/IEEE Design Automation Conference (DAC), 2023 mehr… BibTeX
- GLS Tracing: Gem5-based Low-intrusive Software Tracing. 2022 IEEE Nordic Circuits and Systems Conference (NorCAS), 2022 mehr… BibTeX