Forschungsgebiete
Diese Grafik gibt einen Überblick über unsere Arbeitsgebiete.
Für weitere Informationen klicken Sie bitte auf die Begriffe!
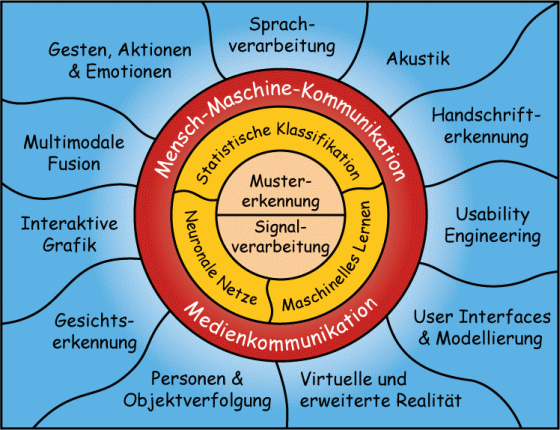
Mensch-Maschine-Kommunikation
Mithilfe moderner Systeme der Informations- und Kommunikationstechnik interagieren wir mit allen Arten von Computern und computergesteuerten Geräten, z.B. um zu telefonieren, um ins Internet zu gehen, um Geräte der Unterhaltungselektronik zu bedienen, um Informationsdienste zu nutzen, um Haushaltsgeräte zu bedienen, oder sogar um Kraftfahrzeuge zu steuern. Diese Systeme sind bereits heute ein integraler Bestandteil unserer Umwelt im täglichen Leben (Stichwort "pervasive computing"). Mit dem technischen Fortschritt werden diese Systeme nicht nur mächtiger und effizienter, sondern zunehmend auch komplexer zu bedienen. Deswegen ist ein adäquates Benutzer-Interface ein wesentliches Ziel von Forschung und Entwicklung, um den mühelosen Zugang zur modernen Informations- und Kommunikationsinfrastruktur zu ermöglichen.
Die Forschung am Lehrstuhl für Mensch-Maschine-Kommunikation beschäftigt sich mit den Grundlagen einer weitgehend intuitiven, natürlichen, und deswegen multimodalen Interaktion zwischen dem Menschen und informationsverarbeitenden Systemen. Alle Formen der Interaktion (d.h. alle Modalitäten), die dem Menschen zur Verfügung stehen, werden dazu untersucht. Sowohl die Informationsdarstellung seitens der Maschine, als auch die Interaktionstechnik muss dabei in Betracht gezogen werden; z.B. Text und Sprache, Schall und Musik, Haptik, Grafik und Gesichtssinn, Gestik und Mimik, und Emotionen.
Klicken Sie bitte auf die weiteren Begriffe der Übersichtsgrafik um mehr über die hier untersuchten Methoden und Anwendungsgebiete zu erfahren.
Medienkommunikation
Im Bereich Medienkommunikation steht die Interaktion des Menschen mit den digitalen Medien im Mittelpunkt der Forschung am Lehrstuhl für Mensch-Maschine-Kommunikation. Wir befassen uns dabei sowohl mit der inhaltlichen Analyse von Multimediadaten (Text, Dokumente, Handschrift, Audio, Grafik, Video), als auch mit Methoden zur Informationsindizierung und Wiedergewinnung aus Datenbanken. Für diese komplexe Mischung von Daten und Inhalten werden einerseits intelligente Methoden zur Musterverarbeitung und -erkennung erforscht und entwickelt, andererseits auch neuartige Interaktionsformen untersucht.
Klicken Sie bitte auf die Begriffe in der unteren Hälfte der Übersichtsgrafik um mehr über die hier untersuchten Anwendungsgebiete zu erfahren.
Mustererkennung
Die Mustererkennung befasst sich mit der Entwicklung und dem Betrieb von Systemen, die Muster in Daten erkennen. Es gibt viele Arten von Mustern, z.B. visuelle Muster, zeitliche Muster, logische Muster, spektrale Muster, usw. Mustererkennung ist ein charakteristischer Bestandteil jedes intelligenten Systems. Es gibt verschiedene Ansätze zur Mustererkennung, unter anderem:
- Statistische oder "fuzzy" Mustererkennung
- Syntaktische oder strukturelle Mustererkennung
- Wissensbasierte Mustererkennung
Der statistische Ansatz sieht Mustererkennung als Klassifikationsaufgabe, d.h. der Zuordnung einer Kategorie zu den anliegenden Eingangsdaten. Damit verbunden sind Teilgebiete wie Merkmalextraktion, Diskriminanzanalyse, Fehlerschätzung, Cluster-Analyse, grammatische Inferenz und Parsing. Bedeutende Anwendungsgebiete sind die Sprach- und Bildverarbeitung, Schrifterkennung, Personenerkennung, industrielle Prüfverfahren, und natürlich die Mensch-Maschine-Kommunikation. Folgerichtig ist die statistische Mustererkennung eine grundlegende wissenschaftliche Disziplin und Forschungsgebiet am Lehrstuhl für Mensch-Maschine-Kommunikation.
Klicken Sie bitte auf die Begriffe der Übersichtsgrafik um mehr über die hier untersuchten Anwendungsgebiete zu erfahren.
Signalverarbeitung
Signalverarbeitung bedeutet Theorie und Anwendung des Filterns, des Codierens, des Übertragens, des Schätzens, des Detektierens, des Analysierens, des Erkennens, des Synthetisierens, des Aufnehmens und des Wiedergebens von Signalen mit digitalen oder analogen Einrichtungen und Verfahren. Der Begriff Signal beinhaltet Audio-, Video-, Sprach-, Bild-, Kommunikations-, medizinische, musikalische, und andere Signale in kontinuierlicher oder diskreter (d.h. abgetasteter) Form. Für die Entwicklung neuer Methoden der Mensch-Maschine-Kommunikation ist Kompetenz in der Signalverarbeitung eine wesentliche Voraussetzung.
Statistische Klassifikation
Die Statistische Klassifikation, für die meist Hidden-Markov-Modelle (HMMs) eingesetzt werden, hat sich in den letzten 20 Jahren als die vermutlich leistungsfähigste Methode zur Verarbeitung dynamischer Muster wie Zeitreihen, Sprachsignale, und anderer Mustersequenzen erwiesen. In der Sprachverarbeitung wurden HMMs zur dominierenden Technologie. In der Multimedia-Signalverarbeitung dagegen, die sich vorwiegend mit Fragestellungen der Bildverarbeitung und Computer Vision befasst, werden HMMs erheblich seltener eingesetzt. In den letzten Jahren wuchs die Bedeutung dieses Anwendungsgebietes, speziell für die Mensch-Maschine-Kommunikation. Wir untersuchen deshalb die Eignung von HMMs für alle Mustererkennungsaufgaben in der Multimedia-Signalverarbeitung, wie etwa:
HMMs in der Sprachverarbeitung. HMMs zur Schrift-, Handschrift- und Formelerkennung. Bildsequenzverarbeitung. Gestenerkennung. Video-indexing mit HMMs und stochastischen Video-Modellen. HMM-basierte audio-visuelle Inhaltsanalyse. Zirkulare 1D- und 2D-HMMs für rotations-invariante Erkennung von Symbolen. Erkennung deformierter und verdeckter Objekte. HMMs für Bilddatenbanken und Bilddatenabfrage. Pseudo-2D-HMMs für die Gesichtserkennung. Pseudo-2D-HMMs für PiKtogrammerkennung und -suche. Personen-Detektion und Objektvefolgung. Gesten- und Gesichtsausdruckerkennung mit 1D- und Pseudo-3D-HMMs.
Ausgewählte Publikationen:
- G. Rigoll, S. Müller: Statistical Pattern Recognition Techniques for Multimodal Human Computer Interaction and Multimedia Information Processing. Survey Paper, Int. Workshop "Speech and Computer", pages 60-69, Moscow, Russia, October 1999 [pdf]
Neuronale Netze
Ein Neuronales Netz (NN) ist eine informationsverarbeitende Struktur, die sich an der stark vernetzten, parallelen Topologie des Gehirns von Säugetieren orientiert. Neuronale Netze verwenden mathematischer Modelle, um die dort beobachteten Eigenschaften biologischer nervöser Systeme nachzubilden und adaptives biologisches Lernen zu ermöglichen. Das Besondere am Aufbau eines Neuronalen Netzes ist die große Zahl untereinander verbundener informationsverarbeitender Elemente (analog zu Neuronen), die durch gewichtete Verbindungen (analog zu Synapsen) miteinander interagieren.
Das Lernen geschieht bei Neuronalen Netzen durch die Anpassung der Verbindungen zwischen den Neuronen. Das Lernen findet beim Training durch Beispiele oder durch verifizierte Input/Output-Datensätze statt, indem der Argorithmus iterativ die Verbindungsgewichte (Synapsen) zwischen den Neuronen adaptiert. Diese Gewichte speichern das Wissen zur Lösung spezieller Aufgaben.
Neuronale Netze werden zur Mustererkennung und für Klassifizierungsaufgaben eingesetzt und können auch verzerrte oder ungenaue Eingangsdaten robust klassifizieren, wie etwa in der Zeichen-, Sprach- und Bilderkennung. Ihre Stärke liegt in der Flexibilität gegenüber Störungen in den Eingangsdaten und ihrer Lernfähigkeit. Neuronale Netze können sowohl in Software, als auch in spezieller Hardware implementiert werden.
Ausgewählte Publikationen:
- Rigoll, G.: Neuronale Netze - Eine Einführung für Ingenieure, Informatiker und Naturwissenschaftler. Reihe "Kontakt & Studium", Expert Verlag, 1994, 274 Seiten.
Maschinelles Lernen
Sprachverarbeitung
Trotz zahlreicher Fortschritte im Bereich der automatischen Spracherkennung ist die Erkennungsleistung und Robustheit heutiger Spracherkennungssysteme nicht ausreichend, um als Grundlage für natürliche, spontansprachliche Mensch-Maschine-Interaktion zu dienen. Ziel der Forschung am Lehrstuhl ist es deshalb, die Genauigkeit von Systemen zur Erkennung natürlicher, fließender Sprache mittels neuartiger Mustererkennungsmethoden zu verbessern. Da die Effizienz der menschlichen Spracherkennung vor allem auf der intelligenten Auswertung von Langzeit-Kontextinformation beruht, verfolgt der Lehrstuhl dabei unter anderem Ansätze zur Berücksichtigung von Kontext auf Merkmalsebene. Ausgehend von sogenannten Tandem-Spracherkennern, bei denen neuronale Netze zur Phonemprädiktion in Kombination mit dynamischen Klassifikatoren verwendet werden, können hierzu bidirektionale Long Short-Term Memory (BLSTM) Netzwerke eingesetzt werden. Im Gegensatz zu derzeit in Tandem-Systemen verwendeten Phonemschätzern erlaubt es das BLSTM-Prinzip, ein optimales Maß an Kontextinformation bei der Prädiktion miteinzubeziehen.
Um die Störgeräuschrobustheit von Spracherkennungssystemen zu verbessern, werden Verfahren zur Verbesserung des Sprachsignals verwendet. Beispielsweise kann durch Nichtnegative-Matrixfaktorisierung ein durch Hintergrundgeräusche gestörtes Sprachsignal in Sprach- und Rauschkomponenten zerlegt werden.
Projekte:
- GLASS:
Generic Live Audio Source Separation (Kooperation mit HUAWEI)
Kontextsensitive automatische Erkennung spontaner Sprache mit BLSTM-Netzwerken (DFG Förderung)
Nichtnegative Matrix-Faktorisierung zur störrobusten Merkmalsextraktion in der Sprachverarbeitung (DFG Förderung) - ASC-INCLUSION
Integrated Internet-Based Environment for Social Inclusion of Children with Autism Spectrum Conditions (EU Förderung im 7. Rahmenprogramm) - U-STAR
Universal Speech Translation Advanced Research (Forschungskooperation)
Ausgewählte Publikationen:
- Martin Wöllmer, Björn Schuller: Probabilistic Speech Feature Extraction with Context-Sensitive Bottleneck Neural Networks", in Neurocomputing, Elsevier, 2012.
- Felix Weninger, Björn Schuller: "Optimization and Parallelization of Monaural Source Separation Algorithms in the openBliSSART Toolkit", Journal of Signal Processing Systems, Springer, 2012. [pdf]
Speaker Diarization
Speaker Diarization ist ein Teilgebiet der Sprachverarbeitung und beschäftigt sich vereinfacht gesagt mit der Fragestellung "Wer spricht wann?". Diese Technologie kann beispielsweise bei der automatischen Auswertung von Meetings zur Anwendung kommen. Das Ziel dabei ist es, die Audio-Aufnahme eines Meetings in Sprecher-homogene Segmente einzuteilen und dann diese Segmente jeweils einem Sprecher zuzuordnen. Die Besonderheit dabei ist, dass die auftretenden Sprecher zunächst unbekannt sind. Um eine Aufnahme zu segmentieren, wird zunächst ein (energie- oder modellbasierter) Ansatz zur Sprachpausenerkennung eingesetzt. Die daraus resultierenden Segmente werden beispielsweise unter Verwendung des Bayesschen Informationskriteriums durch hierarchisches Clustering in wenige Cluster zusammengefasst, so dass optimalerweise jedes Cluster einem Sprecher entspricht. Die Sprecher werden dabei üblicherweise durch Gauss-Mixtur-Modelle (GMMs) repräsentiert.
Ein bisher wenig betrachteter Aspekt dabei ist das Auftreten von überlappender Sprache, d.h. immer wenn mehrere Sprecher gleichzeitig sprechen. Dies kann in den meisten gegenwärtigen Systemen nicht modelliert werden. Daher wird gegenwärtig besonders die Fragestellung betrachtet, wie überlappende Sprache detektiert und weiterverarbeitet werden kann.
Ausgewählte Publikationen:
- J. Geiger, R. Vipperla, S. Bozonnet, N. Evans, B. Schuller, G. Rigoll: " Convolutive Non-Negative Sparse Coding and New Features for Speech Overlap Handling in Speaker Diarization", Proc. INTERSPEECH 2012, ISCA, Portland, OR, USA, 09.-13.09.2012 [pdf]
- J. Geiger, F. Wallhoff, and G. Rigoll. GMM-UBM Based Open-Set Online Speaker Diarization. Proc. INTERSPEECH 2010, Makuhari, Japan, pp. 2330–2333. ISCA, 2010. 26.-30.09.2010 [pdf]
Gesten, Aktionen und Emotionen
Um Mensch-Maschine-Interaktion angenehmer und natürlicher zu gestalten, orientiert man sich in zunehmendem Maße an den Prinzipien der zwischenmenschlichen Kommunikation. Neben der Verwendung intuitiver, natürlicher Modalitäten, wie Sprache, impliziert dies auch, dass z.B. Dialogsysteme über ein gewisses Maß an "sozialer Intelligenz" verfügen sollen. Voraussetzung hierfür ist unter anderem die automatische Erkennung des emotionalen Zustands des Sprechers. Der Lehrstuhl beschäftigt sich daher zusätzlich zur Gesten- und Aktionserkennung mit der automatischen Erkennung von Emotion und sozialen Signalen unter Anderem in Sprache, Text, Musik und Video. Hierzu werden geeignete Verfahren zur Merkmalsextraktion und zur Mustererkennung entwickelt. Um optimale Vergleichbarkeit hinsichtlich der Erkennungsleistung der entwickelten Systeme zu gewährleisten, organisiert der Lehrstuhl jährlich internationale Evaluierungskampagnen, die internationalen Forschungsgruppen die Möglichkeit bieten, ihre Systeme mittels definierten Daten und Aufgabenstellungen zu testen. Zu den Erkennungsaufgaben zählen hierbei neben der Schätzung der aktuellen Emotion eines Benutzers auch andere Zustände und Eigenschaften, wie Interesse und Müdigkeit oder Alter, Geschlecht und Persönlichkeit.
Projekte:
- SEMAINE
Sustained Emotionally coloured Machine-humane Interaction using Nonverbal Expression (EU Förderung im 7. Rahmenprogramm) - ASC-INCLUSION
Integrated Internet-Based Environment for Social Inclusion of Children with Autism Spectrum Conditions (EU Förderung im 7. Rahmenprogramm) - PROMETHEUS
Prediction and interpretation of huMan bEhavior based on probabilistic sTructures and HEteroginoUs Sensors
Ausgewählte Publikationen:
- Hatice Gunes, Björn Schuller: "Categorical and Dimensional Affect Analysis in Continuous Input: Current Trends and Future Directions", in Image and Vision Computing, Special Issue "Affect Analysis in Continuous Input ", Elsevier, 2012.
- Björn Schuller: "The Computational Paralinguistics Challenge", IEEE Signal Processing Magazine, IEEE, 29(4): 97-101, 2012.
Multimodale Fusion
Bei vielen Mustererkennungsaufgaben können mehrere Modalitäten verwendet werden, um aus Datenströmen sinnvolle Information zu extrahieren. So kann z.B. bei der Spracherkennung neben dem Sprachsignal auch visuelle Information (Lippenbewegungen, etc.) ausgenutzt werden, wenn das Sprachsignal gestört ist und eine robustere Erkennung erreicht werden soll. Da Audio- und Videodaten oft mit unterschiedlichen Abtastraten extrahiert werden und Datenströme oft nicht perfekt synchron vorliegen, müssen intelligente Verfahren zur Datenfusion entwickelt werden. Neben sogenannter früher Fusion (Fusion auf Merkmalsebene) und später Fusion (Fusion auf Entscheidungsebene), ist die hybride Fusion eine effiziente Möglichkeit um die Vorteile von früher und später Fusion zu vereinen.
Projekte:
- SEMAINE
Sustained Emotionally coloured Machine-humane Interaction using Nonverbal Expression (EU Förderung im 7. Rahmenprogramm) - ASC-INCLUSION
Integrated Internet-Based Environment for Social Inclusion of Children with Autism Spectrum Conditions (EU Förderung im 7. Rahmenprogramm)
Ausgewählte Publikationen:
- Martin Wöllmer, Marc Al-Hames, Florian Eyben, Björn Schuller, Gerhard Rigoll: "A Multidimensional Dynamic Time Warping Algorithm for Efficient Multimodal Fusion of Asynchronous Data Streams", in Neurocomputing, Elsevier, 73(1-3): 366-380, 2009.
Interaktive Grafik
Bildverarbeitungsbasierte Verfahren erschließen neue Wege der natürlichen Mensch-Maschine-Interaktion. Dazu gehören u.a. die Gestikerkennung zur visuellen Kommandoeingabe, die Objektverfolgung zur Lokalisierung von Personen und Identifizierung ihrer Aktionen, sowie die Gesichtserkennung zur Personalisierung von Interaktionsumgebungen. Neue Dimensionen der Interaktion eröffnen sich durch die Kombination dieser Methoden mit immersiven Technologien wie Augmented oder Virtual Reality.
Gesichtserkennung
Die Erkennungsleistung von Menschen ist, was die Beurteilung und Zuordnung von Gesichtern betrifft, selbst unter widrigsten Umständen, wie beispielsweise Teilverdeckung, Drehung oder optischer Verzerrung, ausgesprochen gut. So können die meisten Menschen leicht eine ihnen bekannte Person in einer größeren Menschenmenge ausfindig machen, selbst bei ungünstigen Sichtverhältnissen.
Hinter dieser evolutionär hervorgebrachten enormen Erkennungsleistung hinken alle bisher entwickelten technischen Systeme weit zurück. Trotz des daraus resultierenden Problems, sich mit dieser Leistung messen zu müssen, wird auf dem Gebiet Gebiet der automatischen Gesichtserkennung intensiv geforscht. Auch die Findung von Gesichtern in beliebigen Bildern sowie die Erkennung von Gesichtsausdrücken und Mimiken ist Bestandteil aktueller Forschung am Lehrstuhl. Zur Modellierung und Erkennung wird ein breites Spektrum der oben erwähnten Methoden zur Signalverarbeitung verwendet.
Automatische Gesichtserkennungssysteme sind auch in einem breiten Spektrum technischer Anwendungen einsetzbar. So ist beispielsweise generell die automatische Zugangskontrolle in Firmeneingangsbereichen heutzutage fast schon in ein produktreifes Stadium gelangt.
Projekte:
Personen- und Objektverfolgung
Projekte:
- Ereignisgesteuerte Zusammenfassung von Überwachungsvideos in Adaptiven Kamera-Netzwerken
(gefördert von der Deutschen Forschungsgemeinschaft) - Synergien von Gangerkennung und Personenverfolgung
(gefördert von der Deutschen Forschungsgemeinschaft) - PROMETHEUS
Prediction and interpretation of huMan bEhavior based on probabilistic sTructures and HEteroginoUs Sensors - AMI
Augmented Multi-party Interaction (funded by EU-IST-Programm) -
M4
Multi-Modal Meeting Manager (funded by EU-IST programme)
Demos:
- Face tracking [avi 1.5MB]
- Tracking Results [avi 14MB]
- Personen-Verfolgung
Die folgenden Videos zeigen Sequenzen, in denen zur Personen-Verfolgung eine Kombination aus Pseudo-2D Hidden-Markov-Modellen und einem Kalman Filter verwendet wurde.
track1 [mpg 0.5MB]
track1b (falls track1 nicht verwendbar) [gif 0.7 MB]
track2 [mpg 0.8 MB]
track3 (PETS2000) [mpg 3.5 MB]
![track1b (falls track1 nicht verwendbar) [gif 0.7 MB]](/fileadmin/w00cgn/mmk/Demos/track3.gif){kind=link}
Personenerkennung anhand der Gangart
Die Erkennung von Personen anhand ihrer biometrischen Merkmale ist ein bereits weit vorangetriebener Forschungsbereich. Das Hauptaugenmerk der Forschung lag dabei vor allem auf den physiologischen Merkmalen, also Gesicht, Iris und Fingerabdruck. Aber auch verhaltensbasierte Merkmale wie Stimme, Unterschrift und Gangart können zur Identifikation herangezogen werden. Im Forschungsbereich "Personenerkennung anhand der Gangart" - auch als "Gait Recognition“ bezeichnet - wird die Gangart einer Person als biometrisches Erkennungsmerkmal herangezogen. Der Hauptvorteil gegenüber den physiologischen Merkmalen liegt in der Möglichkeit Personen auch aus größerer Entfernung und ohne deren unmittelbare Kooperation identifizieren zu können.
Virtuelle und erweiterte Realität
Die Forschungen zum Thema Virtuelle und erweiterte Realität sind am Lehrstuhl MMK interdisziplinär mit den Themen der User Interfaces, der Daten-Visualisierung und der Automotive Forschung verzahnt. Mit unserer State-of-the-Art Ausrüstung können wir nahezu beliebige Anwendungs- und Interaktionsszenarien simulieren und somit reproduzierbare und kontrollierte Bedingungen für Experimente herstellen. Im Bereich der Automotive wird aktiv an der Verbesserung von Head-Up Displays (HUDs) geforscht. Dabei werden vor allem Fragestellungen wie Attention Splitting und mögliche Überdeckungsproblematiken beleuchtet. Dafür stehen verschiedene Fahrsimulatoren zur Verfügung. Außerdem werden in virtuellen Fahrsimulatoren neuartige Interaktions- und Visualisierungstechniken erarbeitet. Daneben forschen wir aktiv an der Interaktion mit Augmented Reality Inhalten sowohl auf Tablets als auch in Head-Mounted Displays. Hierfür steht eine breite Palette an Geräten bereit, angefangen von einfachen Tablets über Geräte wie die "Oculus Rift" bis hin zur immersiven Simulationsplattform (CAVE).
Projekte:
- Hol-I-wood PR
Holonic Integration of Cognition, Communication and Control for a Wood Patching Robot - Immersive Visual Data Mining
User Interfaces und Benutzermodellierung
Egal ob im Automobil, in der industriellen Fertigung oder in der Arbeit mit Menschen mit Behinderung treten User Interfaces aller Art und verschiedenster Modalitäten auf. Dabei kann der Lehrstuhl mit seinen breit gefächerten Arbeitsgebieten aus einer Vielzahl an Möglichkeiten schöpfen, um die passendsten Interaktionsstile zu finden. Oft ist für eine adäquate UI – Implementierung eine Nutzermodellierung wie beispielsweise ein Fahrermodell nötig, die wiederum Rückschlüsse auf das getestete System und Offline-Tests zulässt.
Projekte:
- ASC-INCLUSION
Integrated Internet-Based Environment for Social Inclusion of Children with Autism Spectrum Conditions (EU Förderung im 7. Rahmenprogramm) - Hol-I-wood PR
Holonic Integration of Cognition, Communication and Control for a Wood Patching Robot - SOMMIA
Sprachorientiertes Mensch-Maschine-Interface im Automobil (Kooperation mit Siemens VDO) - ISPA:
Intelligent Support for Prospective Action (Kooperationsversuch für ein LED User Interface mit der MAN Truck and Bus GmbH) - FERMUS:
Fehlerrobuste multimodale Sprachdialoge (Kooperation mit BMW, DaimlerChrysler, Siemens VDO)
Usability Engineering
Durch den sorgfältigen Entwurf und Test neuartiger Dialogkonzepte mithilfe eingehender Usability- und Akzeptanzuntersuchungen entstehen funktionelle Mensch-Maschine-Interfaces, die vom Benutzer als natürlich und angenehm empfunden werden. Hierfür stehen am Lehrstuhl mehrere dafür ausgestattete Labors zur Verfügung.
Die Möglichkeiten reichen von einem Audiolabor über mehrere Fahrsimulatoraufbauten bis hin zu verschiedensten Trackingsystemen (optisches / magnetisches Tracking, Eyetracking).
Projekte:
- Hol-I-wood PR
Holonic Integration of Cognition, Communication and Control for a Wood Patching Robot - SOMMIA
Sprachorientiertes Mensch-Maschine-Interface im Automobil (Kooperation mit Siemens VDO) - ISPA:
Intelligent Support for Prospective Action - TUMMIC:
Thoroughly Consistent User-Centered Man-Machine Interaction in Cars (Kooperation mit der BMW AG)
Handschrifterkennung
Die Ziele der Handschrifterkennung sind eine Steigerung der Benutzerfreundlichkeit durch Stift-basierte Eingabemedien und eine Erhöhung des Automatisierungsgrades für die schnelle und effiziente Bearbeitung und Erkennung von großen Mengen von Schriftstücken. Die automatische Handschrifterkennung kann entweder direkt bei der Eingabe "on-line", als auch zur Erfassung und Verarbeitung von Schriftstücken oder Dokumenten "off-line" erfolgen. On-line bedeutet in diesem Zusammenhang, dass auch die zeitliche Information, also die Trajektorie des Schriftzuges, ausgewertet wird. Im Gegensatz dazu geht die off-line Erkennung von einem Bild aus.
Neben der bekannten OCR (optical character recognition) von maschinengedruckten und digitalisierten Zeichen und der Erkennung handgeschriebener Einzelbuchstaben (z.B. Blockschrift) spielt neuerdings die Erkennung von kursiver Fließschrift eine immer größere Rolle für die Eingabe von Text bei mobilen Geräten.
Beispiele für Anwendungsgebiete sind:
- On-line Handschrifterkennung
Personal Digital Assistant (PDA), Pocket PC, digitizer tablet, Notebook, Webpad, Tablet PC - Off-line Handschrifterkennung
handschriftliche Notizen, Adreßerkennung (Post), Formularverarbeitung - Dokumenterkennung (Maschinenschrift, OCR)
Archivierung (Zeitungen, Rechnungen), Indizierung und Retrieval in Datenbanken, Formulare, Adreßerkennung
Je nach Anwendungsgebiet sind verschiedene Problematiken vordringlich:
- Lokalisierung, Vorverarbeitung und Merkmalextraktion der Schrift
- Erkennung von Einzelzeichen, Worten oder Sätzen
- Segmentierungseigenschaften (Blockschrift, Fließschrift, verbundene oder durchtrennte Schriftzeichen aufgrund geringer Qualität oder Auflösung)
- Anzahl verschiedener Fonts oder Schreiber (schreiberabhängig oder -unabhängig, Adaptionsmöglichkeiten)
- Auswahl eines Wörterbuches (Größe) oder Sprachmodells, Grammatik
Gerade bei der Betrachtung kontinuierlicher Fließschrift, die sich nicht ohne weiteres in Einzelbuchstaben segmentieren läßt, wird die Ähnlichkeit zur Spracherkennung deutlich. In der Spracherkennung, aber auch in zunehmendem Maße in der Schrifterkennung, sind statistische Verfahren zur Mustererkennung (z.B. Hidden-Markov-Modelle) die am häufigstenen verwendete Methode zur Modellierung und Erkennung.
Ausgewählte Publikationen:
- Brakensiek, Anja: Modellierungstechniken und Adaptionsverfahren für die On- und Off-Line Schrifterkennung, Dissertation, TU München, 2002. [pdf]
- Hunsinger, Jörg: Multimodale Erfassung mathematischer Formeln durch einstufig-probabilistische semantische Decodierung. Dissertation, TU München, 2003. [pdf]
Akustik
Technische Akustik und Lärmbekämpfung
Physikalische und gehörbezogene Lärmbeurteilungsverfahren werden entwickelt und in Meßsystemen implementiert. Beim Sound Quality Design wird das gewünschte Klangbild eines Produktes mithilfe psychophysikalischer Methoden entwickelt.
Psychoakustik
Die Eigenschaften des menschlichen Gehörs werden untersucht und bei praktischen Anwendungen berücksichtigt, z.B. bei der Quellencodierung von Audiosignalen, in der Audiologie, beim Audio-Engineering oder in der Raumakustik.
Projekte:
- Audiovisuelle Interaktionen bei der Beurteilung der Lautheit und Lästigkeit von Geräuschen
(gefördert von der DFG)
Demonstrationen:
- Hörbeispiele
Ausgewählte Publikationen:
- Fastl, H., Zwicker, E.: Psychoacoustics: Facts and Models. 3rd updated edition. Berlin/Heidelberg: Springer-Verlag, 2007, 462 S., 313 Abb., CD ROM
- Terhardt, E.: Akustische Kommunikation.Grundlagen mit Hörbeispielen. Berlin/Heidelberg: Springer-Verlag, 1998, 505 S., 221 Abb., Audio-CD.