Field of Research
The chart below gives an overview of our field of research.
Please click on any item to get more information!
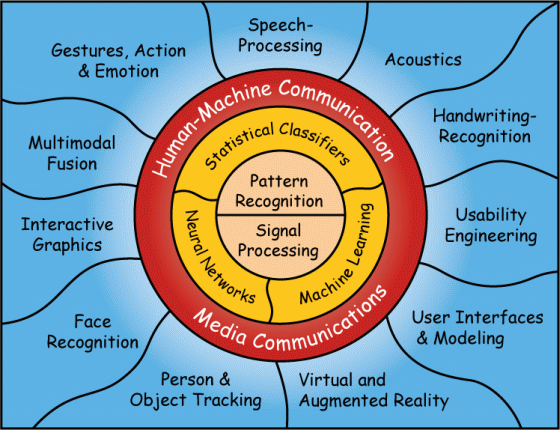
Human-Machine Communication
Modern communication and information processing systems enable us to interact with all kinds of computers and computer controlled machines, e.g. to make a phone call, to access the internet, to operate entertainment electronics, to use information services, to operate household appliances, or even to navigate cars. These systems have already become an inherent part of our environment in everyday life (buzz phrase "pervasive computing"). With ongoing technological progress, these systems do not only become more capable and efficient, but their handling can be rather complex. For this reason, an adequate user interface is a major goal of research and development to enable everyone to participate effortlessly in a modern computing infrastructure.
Research at the Institute for Human-Machine Communication focuses on the fundamentals of a widely intuitive, natural, and therefore multimodal interaction between humans and information processing systems. All forms of interaction, i.e. modalities, that are available to humans, are to be investigated for this purpose. Both the machine's representation of information and the interaction technique is to be considered in this context, like text and speech, sound and music, haptics, graphics and vision, gesture and mimics, and emotions.
Please click on the other items in the overview chart to find out more about methods and application areas investigated at our institute.
Media Communications
In the area of media communications, research at the Institute for Human-Machine Communication focuses on human interaction with digital media technologies. We therefore investigate both the semantic analysis of multimedia data (text, documents, handwriting, audio, graphics, video), and techniques for information indexing and data base retrieval. For this complex mixture of data and content, intelligent pattern processing and recognition methods are explored, and new interaction concepts are developed.
Click on the items in the lower part of the overview chart to find out more about the application areas investigated at our institute.
Pattern Recognition
Pattern recognition is the research area that studies the design and operation of systems that recognize patterns in data. There are many kinds of different patterns, e.g. visual patterns, temporal patterns, logical patterns, spectral patterns, etc. Pattern recognition is an inherent part of every intelligent activity or system. There are different approaches to pattern recognition, including:
- Statistical or fuzzy pattern recognition
- Syntactic or structural pattern recognition
- Knowledge-based pattern recognition
The statistical approach views pattern recognition as classification task, i.e. assigning an input to a category, based on statistical criteria. It encloses subdisciplines like discriminant analysis, feature extraction, error estimation, cluster analysis, grammatical inference and parsing. Important application areas are speech and image analysis, character recognition, man and machine diagnostics, person identification, industrial inspection, and of course, human-machine interaction. Consequentially, the area of statistical pattern recognition is a fundamental scientific discipline and area of research at the Institute for Human-Machine Communication.
Click on the items in the overview chart to find out more about the application areas investigated at our institute.
Signal Processing
Signal Processing means the theory and application of filtering, coding, transmitting, estimating, detecting, analyzing, recognizing, synthesizing, recording, and reproducing signals by digital or analog devices or techniques. The term signal includes audio, video, speech, image, communication, medical, musical, and other signals in continous or discrete (i.e. sampled) form. Competence in Signal Processing is vital for the development of new techniques in Human-Machine Communication.
Statistical Classifiers
Statistical Classifiers like Hidden Markov Models (HMMs) have emerged during the last 20 years as probably the most powerful paradigm for processing of dynamic patterns, such as time series, speech signals, and other pattern sequences. Especially in speech recognition, HMMs became the dominating technology. However, in multimedia signal processing applications, involving mostly image processing and computer vision problems with dynamic and static patterns, HMMs are still far less often used. But this area became more and more important during recent years, especially in Human-Machine Communication. We therefore investigate the suitability of HMMs with respect to various pattern recognition tasks in multimedia information processing, like:
HMMs in speech recognition. HMMs for character, handwriting and formula recognition. Image sequence processing with HMMs. HMMs for gesture recognition. Video-indexing with HMMs and stochastic video models. HMM-based audio-visual topic recognition. Circular 1D- and 2D-HMMs for rotation-invariant recognition of symbols. Recognition of deformed and occluded objects. HMMs in image databases and image retrieval. Pseudo-2D-HMMs for face recognition. Pseudo-2D-HMMs for pictogram recognition and spotting. HMM-applications for person detection and object tracking. Gesture and facial expression recognition with 1D- and Pseudo-3D-HMMs.
Selected Publications
- G. Rigoll, S. Müller: Statistical Pattern Recognition Techniques for Multimodal Human Computer Interaction and Multimedia Information Processing. Survey Paper, Int. Workshop "Speech and Computer", pages 60-69, Moscow, Russia, October 1999 [pdf]
Neural Networks
A Neural Network (NN) is an information-processing structure inspired by the interconnected, parallel topology of the mammalian brain. NNs use a collection of mathematical models to emulate some of the observed properties of biological nervous systems and draw on the analogies of adaptive biological learning. The key element of the NN paradigm is its structure composed of a large number of interconnected processing elements that are analogous to neurons and that are tied together with weighted connections that are analogous to synapses.
Learning in NNs involves adjustments to the connections that exist between the neurons. Learning typically occurs by example through training, or exposure to a set of verified input/output data where the training algorithm iteratively adjusts the connection weights (synapses). These connection weights store the knowledge necessary to solve specific problems.
NNs are used for pattern recognition and classification tasks, with the ability to robustly classify imprecise input data, such as in character, speech and image recognition. The advantage of NNs lies in their resilience against distortions in the input data and their capability of learning. NNs can be implemented in software or in specialized hardware.
Selected Publications
- Rigoll, G.: Neuronale Netze - Eine Einführung für Ingenieure, Informatiker und Naturwissenschaftler. Reihe "Kontakt & Studium", Expert Verlag, 1994, 274 Seiten.
Speech Processing
In spite of recent progress in automatic speech recognition, the accuracy and robustness of today's speech recognition systems is still not sufficient to serve as a basis for natural, spontaneous human-machine interaction. Therefore, the goal of the research done at the institute is to improve the accuracy of systems for the recognition of natural, fluent speech via novel pattern recognition techniques. Since the efficiency of human speech recognition heavily relies on the intelligent exploitation of long-term context information, the institute focuses on methods that exploit context on the feature level. Starting from so-called Tandem speech recognizers, in which neural networks are used for phoneme prediction in combination with dynamic classifiers, one such technique is the application of bidirectional Long Short-Term Memory (BLSTM) networks. In contrast to commonly used phoneme predictors in Tandem systems, the BLSTM principle allows for an integration of an optimal amount of context during phoneme prediction.
In order to improve the noise robustness of speech recognition systems, speech enhancement methods are used. For example, using Non-Negative Matrix Factorization, a speech signal distorted by background noise can be separated into speech and noise components.
Projects:
- GLASS:
Generic Live Audio Source Separation (Cooperation with HUAWEI)
Context-Sensitive Automatic Recognition of Spontaneous Speech by BLSTM Networks (DFG funded)
Non-Negative Matrix Factorization for Robust Feature Extraction in Speech Processing (DFG funded) - ASC-INCLUSION
Integrated Internet-Based Environment for Social Inclusion of Children with Autism Spectrum Conditions (EU funded, 7th framework programme) - U-STAR
Universal Speech Translation Advanced Research (research cooperation)
Selected publications:
- Martin Wöllmer, Björn Schuller: Probabilistic Speech Feature Extraction with Context-Sensitive Bottleneck Neural Networks", in Neurocomputing, Elsevier, 2012.
- Felix Weninger, Björn Schuller: "Optimization and Parallelization of Monaural Source Separation Algorithms in the openBliSSART Toolkit", Journal of Signal Processing Systems, Springer, 2012. [pdf]
Speaker Diarization
Speaker Diarization is a subdomain of speech processing and basically is about answering the question "Who speaks when?". This technology can be applied in the automatic meeting analysis. Thereby, the goal is to divide the audio recording of a meeting into speaker-homogeneous segments and then assign a speaker to each segment. The speciality here is that the occurring speakers are unknown beforehand. To segment a recording, first a (energy- or model-based) approach for voice activity detection is applied. The resulting segments are then grouped into a few clusters with a hierarchical clustering approach, whereby the Bayesian Information Criterion (BIC) can be employed.
Ideally, each of the clusters then represents one speaker. Usually, speakers are modelled with Gaussian Mixture models (GMMs).
Until now, handling of overlapping speech (where multiple speakers are speaking simultaneously) was barely addressed. In most current system, this can not be modelled. Therefore, attention is now given particularly to the question how overlapping speech can be detected and further processed.
Selected publications:
- J. Geiger, R. Vipperla, S. Bozonnet, N. Evans, B. Schuller, G. Rigoll: " Convolutive Non-Negative Sparse Coding and New Features for Speech Overlap Handling in Speaker Diarization", to appear in Proc. INTERSPEECH 2012, ISCA, Portland, OR, USA, 09.-13.09.2012 [pdf]
- J. Geiger, F. Wallhoff, and G. Rigoll. GMM-UBM Based Open-Set Online Speaker Diarization. Proc. INTERSPEECH 2010, Makuhari, Japan, pp. 2330–2333. ISCA, 2010. 26.-30.09.2010 [pdf]
Gestures, Action and Emotion
To make human-machine interaction more pleasant and natural, principles of interhuman communication are increasingly used as an example. Besides the application of intuitive, natural modalities, such as speech, this also implies that dialog systems need to have a certain degree of "social intelligence". A precondition for this is the automatic recognition of a speaker's emotional state. Thus, in addition to gesture and action recognition, the institute also focuses on the automatic recognition of emotion and social signals from speech, text, music, and video. To this end, suitable techniques for feature extraction and pattern recognition are developed. To enable comparability with respect to the recognition performance of the developed systems, the institute organizes annual international evaluation challenges so that international research groups have the possibility to test their systems using defined data sets and recognition tasks. Such recognition tasks comprise the estimation of the current emotion of a speaker, but also other speaker states and traits such as interest and sleepiness or age, gender and personality.
Projects:
- SEMAINE
Sustained Emotionally coloured Machine-humane Interaction using Nonverbal Expression (EU funded, 7th framework programme) - ASC-INCLUSION
Integrated Internet-Based Environment for Social Inclusion of Children with Autism Spectrum Conditions (EU funded, 7th framework programme) - PROMETHEUS
Prediction and interpretation of huMan bEhavior based on probabilistic sTructures and HEteroginoUs Sensors
Selected publications:
- Hatice Gunes, Björn Schuller: "Categorical and Dimensional Affect Analysis in Continuous Input: Current Trends and Future Directions", in Image and Vision Computing, Special Issue "Affect Analysis in Continuous Input ", Elsevier, 2012.
- Björn Schuller: "The Computational Paralinguistics Challenge", IEEE Signal Processing Magazine, IEEE, 29(4): 97-101, 2012.
Multimodal Data Fusion
Various pattern recognition tasks offer the possibility to use multiple modalities in order to extract useful information from data streams. For example, during speech recognition, also visual information (lip movements, etc.) can be exploited in addition to the speech signal in case the speech signal is distorted and if a more robust recognition should be enabled. As audio and video data are often sampled at different sampling frequencies and since data streams can often not be assumed to be perfectly synchronous, intelligent techniques for data fusion have to be developed. Next to so-called early fusion (fusion on the feature level) and late fusion (fusion on the decision level), hybrid fusion is an efficient possibility to unite the advantages of early and late fusion.
Projects:
- SEMAINE
Sustained Emotionally coloured Machine-humane Interaction using Nonverbal Expression (EU Förderung im 7. Rahmenprogramm) - ASC-INCLUSION
Integrated Internet-Based Environment for Social Inclusion of Children with Autism Spectrum Conditions (EU Förderung im 7. Rahmenprogramm)
Selected Publications:
- Martin Wöllmer, Marc Al-Hames, Florian Eyben, Björn Schuller, Gerhard Rigoll: "A Multidimensional Dynamic Time Warping Algorithm for Efficient Multimodal Fusion of Asynchronous Data Streams", in Neurocomputing, Elsevier, 73(1-3): 366-380, 2009.
Interactive Graphics
Techniques based on image processing render new ways of natural human-machine interaction possible. These include gesture recognition for visual command input, object tracking for locating people and identifying their actions, and face recognition to personalize interactive environments. New dimensions for interaction open up by combining these methods with immersive technologies like Augmented or Virtual Reality.
Face Recognition
The recognition performance of human beings concerning the classification of faces even under contrarious constraints, such as partial occlusions, rotation or visual distortion can be seen as extremely good. Such most people can easily spot known individuals in larger groups, even under disadvantageous conditions.
Today all known technical systems are far beyond those enormous evolutionary grown recognition capabilities. However, despite the resulting problem to mess a technical system with the performance of human beings, automated face recognition is still an active field of resarch. In addition to this, the finding of faces in abritry images as well as the recognition of facial expressions and mimiks is focus of serveral activies within our institute. The modeling and classfication is done using a wide range of signal processing methods mentioned above.
Automated systems for face recognition enable a wide spectrum for technical applications. For example automated entrance systems for companies have nearly reached a stadium to be mature for serial prudcts nowadays.
Projects::
Person and Object Tracking
Projects:
- Augmented Synopsis of Surveillance Videos in Adaptive Camera Networks
(funded by the Deutsche Forschungsgemeinschaft DFG) - SOTAG - SynergiesOfTrackingAndGait
(funded by the Deutsche Forschungsgemeinschaft DFG) - PROMETHEUS
Prediction and interpretation of huMan bEhavior based on probabilistic sTructures and HEteroginoUs Sensors - AMI
Augmented Multi-party Interaction (funded by EU-IST-Programm) -
M4
Multi-Modal Meeting Manager (funded by EU-IST programme)
Demos:
- Face tracking [avi 1.5MB]
- Tracking Results [avi 14MB]
- Person tracking
The following videos contain example sequences of tracking persons using a combination of a Pseudo-2D Hidden Markov Model and a Kalman Filter.
track1 [mpg 0.5MB]
track1b (falls track1 nicht verwendbar) [gif 0.7 MB]
track2 [mpg 0.8 MB]
track3 (PETS2000) [mpg 3.5 MB]
![track1b (falls track1 nicht verwendbar) [gif 0.7 MB]](/fileadmin/w00cgn/mmk/Demos/track3.gif){kind=link}
Person identification based on gait
Person identification by their biometric features is a well established research area. The main focus has so far been on physiologic features such as face, iris and fingerprint. In addition, behavior based features such as voice, signature and gait can be used for person identification. In the research on person identification based on gait - also called "gait recognition" - the way people walk is used as a biometric feature for person identification. The main advantage of using these features over other physiologic features is the possibility to identify people from large distances and without the person’s direct interaction.
Virtual and Augmented Reality
Research into Virtual Reality (VR) and Augmented Reality (AR) at the Institute for Human-Machine-Communication is densely linked to ongoing research in User Interfaces, Data Visualization and Automotive User Design. Our state-of-the-art equipment can provide virtually any application- or interaction-scenario in a controlled immersive environment (CAVE). This is of special benefit to user experiments where repeatability is indispensable while the controlled conditions help reduce experimental noise. The automotive group is actively working on the enhancement of head-up displays (HUDs). In this context the main focus lays on attention splitting and the content covering problems. This is done using both a real and a virtual driving simulator. Furthermore, the virtual driving simulator is used to develop novel interaction- and visualization techniques within the car. Our current research into augmented reality draws on our expertise in VR and examines content visualization and interaction on a wide range of devices.
Projects:
- Hol-I-wood PR
Holonic Integration of Cognition, Communication and Control for a Wood Patching Robot - Immersive Visual Data Mining
User Interfaces and Modeling
Whether in the automotive field, industrial production or interaction with disabled people there exist User Interfaces of all kinds which apply various modalities. From its broad area of work the institute can chose from a wealth of possibilities to find the most suitable interaction styles. In many cases the sophisticated UI demands for modeling the user (e.g. a driver model) which in turn provides insight on the developed system and enables offline tests.
Projects:
- ASC-INCLUSION
Integrated Internet-Based Environment for Social Inclusion of Children with Autism Spectrum Conditions (EU Förderung im 7. Rahmenprogramm) - Hol-I-wood PR
Holonic Integration of Cognition, Communication and Control for a Wood Patching Robot - SOMMIA
Sprachorientiertes Mensch-Maschine-Interface im Automobil (Kooperation mit Siemens VDO) - ISPA:
Intelligent Support for Prospective Action (Kooperationsversuch für ein LED User Interface mit der MAN Truck and Bus GmbH) - FERMUS:
Fehlerrobuste multimodale Sprachdialoge (Kooperation mit BMW, DaimlerChrysler, Siemens VDO)
Usability Engineering
The thorough design of novel UIs and dialog concepts includes sophisticated usability testing and acceptance studies. Such approaches lead to interfaces that are perceived natural and comfortable. The institute offers several labs for such investigations.
Possibilities range from an audio lab, several driving simulator mock-ups to various tracking systems (optical, magnetic, eyetracking).
Projects:
- Hol-I-wood PR
Holonic Integration of Cognition, Communication and Control for a Wood Patching Robot - SOMMIA
Speech Oriented Man-Machine-Interface in the Automobile (Cooperation with Siemens VDO) - ISPA:
Intelligent Support for Prospective Action - TUMMIC:
Thoroughly Consistent User-Centered Man-Machine Interaction in Cars (Cooperation with BMW AG)
Handwriting Recognition
The goal of automatic handwriting recognition is to enhance user-friendliness through pen-based input devices and to increase automation for fast and efficient processing of large amounts of documents. Automatic handwriting recognition can either be done at the time of input "on-line", or "off-line" when processing documents. On-line means in this context that time-information, i.e. the trajectory of the strokes, is processed as well. In contrast to this, off-line recognition only uses a picture.
Besides the well-known OCR (optical character recognition) of machine-printed and digitized characters and the recognition of single handwritten characters, the recognition of cursive longhand plays a growing role for the input of text in mobile devices.
Samples for application are:
- On-line handwriting recognition
Personal Digital Assistant (PDA), Pocket PC, digitizer tablet, Notebook, Webpad, Tablet PC - Off-line handwriting recognition
handwritten notes, address recognition (mail), form processing - Document recognition (OCR)
archiving (newspapers, bills), indexing and retrieval in data bases, form processing, address recognition
Depending on the application, different questions prevail:
- localization, preprocessing and feature extraction of the script
- recognition of single characters, words or sentences
- segmentation properties (block letters, longhand, connected or divided characters because of low quality or resolution)
- number of different fonts or writers (writer independent or not, adaptation)
- choice of a codebook (size) or language model, grammar
Recognizing continous cursive longhand, which cannot be easily segmented in single characters, is quite similar to a speech recognition task. For this task, and for handwriting recognition as well, statistical methods for pattern recognition (e.g. Hidden Markov Models) are the most common technique for modeling and recognition.
Selected Publications:
- Brakensiek, Anja: Modellierungstechniken und Adaptionsverfahren für die On- und Off-Line Schrifterkennung, Dissertation, TU München, 2002. [pdf]
- Hunsinger, Jörg: Multimodale Erfassung mathematischer Formeln durch einstufig-probabilistische semantische Decodierung. Dissertation, TU München, 2003. [pdf]
Acoustics
Technical Acoustics and Noise Abatement
Physical and hearing-related methods for the evaluation of noise are developed and implemented in measuring systems. Sound Quality Design refers to creating the desired sound characteristics of industrial products using psychophysical methods.
Psychoacoustics
The properties of the human auditory system are being investigated and considered in practical applications, e.g. in the context of source coding of audio signals, audiology, audio engineering technology or room acoustics.
Projects:
Demos:
- Acoustic Demonstrations
Selected Publikations:
- Fastl, H., Zwicker, E.: Psychoacoustics: Facts and Models. 3rd updated edition. Berlin/Heidelberg: Springer-Verlag, 2007, 462 S., 313 Abb., CD ROM
- Terhardt, E.: Akustische Kommunikation.Grundlagen mit Hörbeispielen. Berlin/Heidelberg: Springer-Verlag, 1998, 505 S., 221 Abb., Audio-CD.