Auditory Modeling
Auditory models help us understand the mechanisms of the human auditory system. Using digital signal processing algorithms we model the auditory nerve’s response and analyze features available with two ears. This gives insight into the mechanisms of hearing and for understanding speech in noisy and dynamic listening scenarios. Models are also key to improving algorithms for cochlear implants and hearing aids and to evaluating the sound quality of sound field synthesis methods.
Our models are available on the AIP’s ZENODO page and on our download page.
Key findings
- A phenomenological model for the temporal response of an auditory nerve fiber to an electric pulse of flexible shape (Horne, Sumner & Seeber, 2016)
- Extension of the electrical stimulation model of auditory nerve fibers to pulse train stimuli: a “cochlear implant model” (e.g., Takanen & Seeber, CIAP 2017; Takanen & Seeber, DAGA 2017).
- Patient-individual fitting of auditory nerve for cochlear implants (Seeber, Takanen & Werner, 2019; Werner & Seeber, CIAP 2017, Werner & Seeber, Bernstein Conf. 2017)
- Fast processing explains the effect of sound reflection on binaural unmasking (Kolotzek, Aublin & Seeber; arXiv 2021)
Phenomenological model of the electrically stimulated auditory nerve fiber
A special interest lies in modeling the response of the auditory nerve fiber to electrical stimulation in cochlear implants (Seeber & Bruce, 2016; Takanen, Bruce & Seeber, 2016) and the percepts of implant users. To this end, we have developed a phenomenological model for the electrically stimulated auditory nerve fiber as an extension of our previous single pulse model (Horne & Seeber, 2016) that is capable of reproducing response characteristics for pulse train stimuli. For pulse trains, individual pulses interact on a neural level, and the model takes into account the effects of refractoriness, facilitation and accommodation (Takanen & Seeber, CIAP 2017; Takanen & Seeber, Bernstein Conf. 2017; Takanen & Seeber, DAGA 2017).

The ongoing cochlear implant research at the AIP aims at using these models to improve stimulation strategies of cochlear implants. Toward this aim, we fit parameters of the model to individual patients to gain patient-individual predictions of the nerve response (Werner & Seeber, CIAP 2017; Werner & Seeber, Bernstein Conf. 2017). The fitting procedure and the validation of the patient-specific model is based on psychophysical and electrophysiological measurements. The objective is to obtain a model that predicts the temporal response of individual auditory nerve fibers, and to use this approach to develop and evaluate stimulation algorithms with the aim to improve speech understanding in critical conditions.
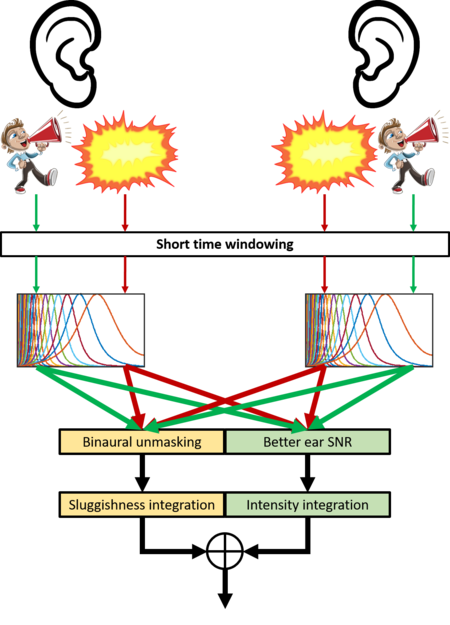
Binaural unmasking
Humans detect sound sources better if the sound and the interfering noise source are located at different positions. This ability is based on differences between the left and right ear signals that depend on the position of the sound source. If the sound source is moving (Kolotzek & Seeber; ICA 2019), these interaural differences will change over time and room reflections will cause additional changes (Kolotzek, Aublin & Seeber, DAGA 2021). From previous studies, it is thought that the auditory system cannot process fast temporal changes of interaural differences. Our current modelling approach instead achieves best performance when interaural differences are computed in short time instances, which are subsequently smoothed over time. The modelling work thus suggests that the auditory system processes binaural cues from short time snippets to aid sound detection in reverberant situations (Kolotzek, Aublin & Seeber; arXiv 2021).
Team members involved in auditory modeling
Current:
Norbert F. Bischof, M.Sc.
Dipl.-Ing. Matthieu Kuntz
L'uboš Hládek, PhD
Past:
Kauê Werner, M.Eng.
Dr. Colin Horne
Dr. Marko Takanen
External funding
2011-2014: Colin Horne, Medical Research Council UK studentship
2012-2022: Bernstein Center for Computational Neuroscience Munich, project C5 (BMBF grant 01 GQ 1004B).
2016-2017: Smartstart Grant in Computational Neurosciences for Kauê Werner
2017-2018: DAAD Scholarship for Kauê Werner
2018-2022: Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) – Projektnummer 352015383 – SFB 1330 C5.
Selected Publications
- Seeber, B.U.; Bruce, I.: The history and future of neural modelling for cochlear implants. Network: Computation in Neural Systems (Vol. 27, Issue 2-3), 2016, 53-66
- Takanen, M.; Bruce, I.C.; Seeber, B.U.: Phenomenological modelling of electrically stimulated auditory nerve fibers: A review. Network: Computation in Neural Systems (Vol. 27, Issue 2-3), 2016, 157-185
- Horne, C.; Sumner, C.S.; Seeber, B.U.: A phenomenological model of the electrically stimulated auditory nerve fiber: temporal and biphasic response properties. Frontiers in Computational Neuroscience (Vol. 10, No. 8), 2016
- Takanen, M.; Seeber, B.U.: A Phenomenological Model for Predicting Responses of Electrically Stimulated Auditory Nerve Fiber to Ongoing Pulsatile Stimulation. Conf. on Implantable Auditory Prostheses, 2017, 91, M11a
- Takanen, M.; Seeber, B.U.: Reproducing response characteristics of electrically-stimulated auditory nerve fibers with a phenomenological model. JASA, Acoustics '17 Boston, 2017, 3629-3630, 2pPPa4
- Takanen, M.; Seeber, B.U.: Phenomenological modeling of the electrically stimulated binaural auditory system. Proc. Bernstein Conference, 2017, T94
- Takanen, M.; Weller, J.-N.; Seeber, B.U.: Modeling Refractoriness In Phenomenological Models of Electrically-Stimulated Auditory Nerve Fibers. Fortschritte der Akustik -- DAGA '17, 2017, 468-470
- Werner, K.; Leibold, C.; Seeber, B.U.: Individual fitting and prediction with a phenomenological auditory nerve fiber model for CI users. Conf. on Implantable Auditory Prostheses, CIAP, 2017, p. 92, M11b
- Werner, K.; Leibold, C.; Seeber, B.U.: Individual fitting of neural population latency distribution with a phenomenological auditory nerve fiber model for cochlear implant users. Proc. Bernstein Conference, 2017